Last week I asked Claude Code to help me refactor a statistical analysis script. It asked: "Python or R?" I had written "use R for statistics" in my config file three months ago, but the context from that conversation was long gone. This is the most fundamental limitation of AI agents: when a conversation ends, memory resets to zero.
If you only chat with AI occasionally, amnesia is not a big deal. But when you want AI to be a long-term work partner handling literature reviews, writing code, and managing projects every day, "forgetting everything" becomes a fatal flaw.
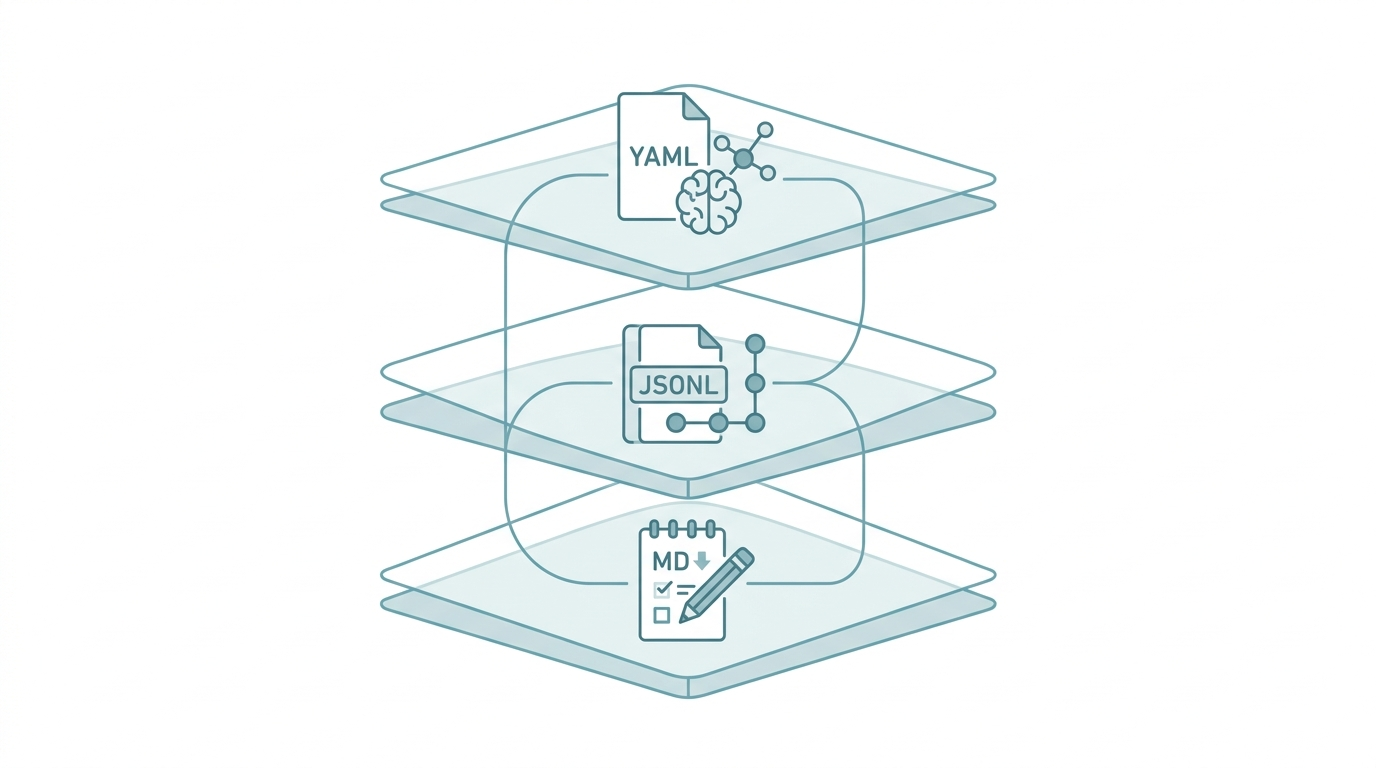
The three-layer memory architecture is a design pattern for AI agent memory systems that divides information into three tiers — fact, episodic, and scratchpad — each responsible for different time scales and access patterns, enabling AI to maintain contextual continuity across conversations and tasks.
I am an assistant professor at Yuanpei University of Medical Technology and R&D director at a biotech company. Over the past six months, I have been running this architecture with Claude Code in production. This article explains the design philosophy behind "why three layers" and the concrete implementation of each layer.
Why a Single File Does Not Work
The most intuitive approach is to open one memory.md and dump everything in. That is exactly what I did at first.
Two weeks later the file had ballooned past 500 lines, mixing personal preferences, last week's technical decisions, current task scratch notes, and three-month-old pitfall records. The AI had to read the entire file on every startup, wasting massive amounts of tokens on irrelevant content. Worse, things that should be kept and things that should be discarded were tangled together, and I had no idea what could be safely deleted.
The root problem: different types of memory have different lifecycles and access patterns. Your name and language preference never change, but yesterday's task notes will be useless tomorrow. An architectural decision from six months ago occasionally needs revisiting, but should not be loaded into every conversation.
That is why you need layers.
Design Philosophy of the Three-Layer Architecture
The three-layer architecture draws inspiration from how human memory works. Our brains do not store all memories in one place either:
| Memory Layer | Human Memory Analogy | AI Implementation | Lifecycle | Access Frequency |
|---|---|---|---|---|
| Fact Layer | Semantic memory (knowledge, facts) | fact.yml |
Long-term stable | Every startup |
| Episodic Layer | Episodic memory (experiences, events) | episodic.jsonl |
Long-term cumulative | On-demand query |
| Scratchpad Layer | Working memory (current task) | scratchpad.md |
Short-term | During task |
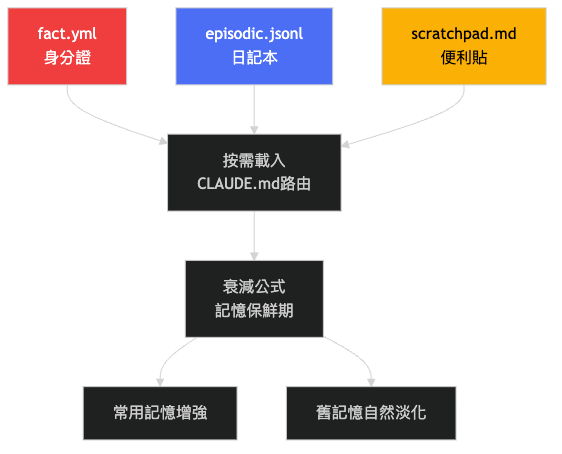
The core principle of this layering is load on demand. Rather than cramming all memories into the context window at startup, you load only the layer most relevant to the current task.
Fact Layer: Who You Are, What Your Rules Are
The fact layer is stored in YAML format as fact.yml. It records stable, rarely changing, structured information:
user:
name: CYHsieh
language: "Traditional Chinese, Taiwan (strict)"
timezone: "Asia/Taipei (GMT+8)"
roles:
- org: Yuanpei University of Medical Technology
title: Assistant Professor
- org: YCBio
title: R&D Director
preferences:
statistics_workflow:
primary_language: "R"
rule: "Use R for hypothesis testing, effect sizes, publication-grade charts; Python for everything else"
tech_stack: ["Tailwind CSS", "React", "Zod"]
language_rules:
forbidden_words:
- "software → use local equivalent"
- "information → use local equivalent"
- "video → use local equivalent"
Why YAML instead of Markdown? Because fact-layer data needs to support structured queries. When the AI wants to know "what is this user's preferred statistics language," pulling the value directly from preferences.statistics_workflow.primary_language is far more reliable than parsing a natural language paragraph.
The fact layer's update strategy is append-only. Existing entries are never deleted; instead, an archived: true flag is added. This keeps every historical setting traceable.
Every time Claude Code starts, the fact layer is pulled in via CLAUDE.md's memory routing. It is the foundation for the AI "knowing who you are."
Episodic Layer: What Has Happened
The episodic layer uses JSONL format (one JSON object per line) as episodic.jsonl. It records events, decisions, and lessons learned:
{"ts":"2026-03-15T14:30:00+08:00","type":"decision","summary":"Statistics language set to R","detail":"Use R for hypothesis testing / effect sizes / charts; Python for other engineering tasks","tags":["statistics","R","tooling"]}
{"ts":"2026-04-02T09:15:00+08:00","type":"failure","summary":"AI accidentally deleted config file","detail":"Claude Code ran a cleanup script that removed .env.local, crashing the dev environment","lesson":"Establish a Hook gatekeeper system to prohibit rm commands","tags":["safety","hook","incident"]}
{"ts":"2026-05-10T16:00:00+08:00","type":"milestone","summary":"Memory system v4.0 launched","detail":"Strength decay formula: base(imp/10) + retrieval(count*0.08) + assoc(edges*0.05) - decay(weeks*0.03)","tags":["memory","architecture"]}
Why JSONL over YAML or Markdown? Three reasons:
- Naturally append-only friendly. Each record is an independent line. Appending never risks corrupting existing content
- Programmatically filterable. Want "all failure-type records" or "decisions from the last two weeks"? A single
jqcommand handles it - Volume control. You never need to load everything. The AI can filter relevant episodes by matching the current task's tags
The episodic layer is not auto-loaded on every startup. It is designed for on-demand queries. When the AI encounters a similar problem (say, choosing a statistics language again), it goes back to the episodic layer: "Have I made a similar decision before?" This prevents stepping on the same rake twice.
Scratchpad Layer: What You Are Doing Right Now
The scratchpad layer uses Markdown format as scratchpad.md. It is the shortest-lived memory, recording current task progress, to-dos, and temporary notes.
# Scratchpad - Current Task
## In Progress: Statistical Analysis Script Refactor
- [x] Read original Python script
- [x] Confirm switching to R's rstatix package
- [ ] Rewrite hypothesis testing section
- [ ] Generate effect size charts
## Temporary Notes
- Dataset located at data/experiment_2026Q1.csv
- Client requires Cohen's d, not Hedge's g
The scratchpad exists to solve the cross-session handoff problem. If a task gets interrupted midway, the next time a new session starts the AI reads scratchpad.md and picks up right where it left off, without you having to re-explain "where did we leave off."
The scratchpad's cleanup strategy is manual or periodic. After a task is complete, important decisions should be "promoted" to the episodic layer, and the scratchpad is cleared for the next task.
How the Three Layers Collaborate
The three memory layers do not operate in isolation. There is a clear flow between them:
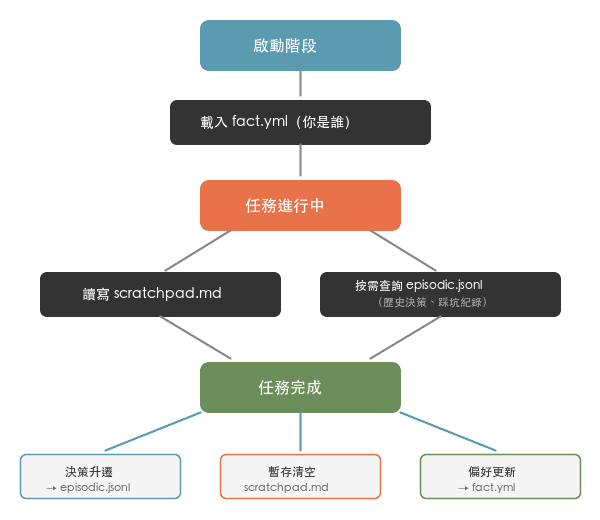
- Startup phase: CLAUDE.md triggers, loading the fact layer (fact.yml). The AI knows who you are and your preferences
- During a task: The scratchpad (scratchpad.md) is updated in real time. When a decision requires historical reference, the episodic layer (episodic.jsonl) is queried
- After task completion: Key decisions from the scratchpad are "promoted" to the episodic layer. The scratchpad is cleared
- Preference changes: If the task reveals a need to update a long-term preference (e.g., "always use R for statistics from now on"), it gets written to the fact layer
Startup -> Load fact.yml (who you are)
|
During -> Read/write scratchpad.md (what you are doing now)
| when historical reference is needed
Query episodic.jsonl (what has happened before)
|
Done -> Promote decisions to episodic.jsonl
Clear scratchpad
Update fact.yml (if applicable)
The key design here is CLAUDE.md as the routing entry point. It does not store memory content itself; it tells the AI "where to find what." This keeps the entire system modular, with each layer independently extensible.
For a complete treatment of the CLAUDE.md routing design, see CLAUDE.md Design Philosophy: Making AI Remember Who You Are.
Building from Scratch: Three Steps
If you want to set up a three-layer memory system in your own Claude Code project, here is the minimum viable starting point:
Step 1: Create the memory directory and fact layer
mkdir -p memory
cat > memory/fact.yml << 'EOF'
user:
name: "Your Name"
language: "Traditional Chinese, Taiwan"
timezone: "Asia/Taipei"
preferences:
tech_stack: ["your preferred frameworks"]
EOF
Step 2: Create the scratchpad layer
cat > memory/scratchpad.md << 'EOF'
# Scratchpad - Current Task
(Record task progress here when a task begins)
EOF
Step 3: Add memory routing in CLAUDE.md
## Memory Routing
- Preferences/settings: memory/fact.yml
- Task scratch notes: memory/scratchpad.md
The episodic layer (episodic.jsonl) can wait until you actually need to record a decision. You do not need to populate all three layers from day one; the system grows naturally with use. Once fact.yml reaches a certain size, you will naturally want to split it into domain-specific files like fact_tools.yml or fact_sop.yml. Do that when the pain arrives, not before.
Advanced: Memory Strength and Decay
Once the episodic layer accumulates hundreds of entries, "which memories matter more" becomes a real question. I designed a simple memory strength formula:
strength = base(importance/10)
+ retrieval(count * 0.08)
+ association(edges * 0.05)
- decay(weeks * 0.03)
Each episodic memory's strength is determined by four factors: initial importance, how many times it has been revisited, the number of associations with other memories, and natural decay over time. Memories that drop below a threshold are flagged as archivable, but never deleted.
This mechanism ensures that truly important experiences (like "that time the AI accidentally deleted a file") remain high-strength because they are referenced repeatedly, while trivial scratch records fade out naturally.
Beyond Three Layers: How the System Grows
After a few months of daily use, the three-layer architecture naturally sprouted new structures:
- Association graph: Episodes are not isolated. "AI deleted .env.local" and "built Hook gatekeeper system" share a causal link. I added an
associations.jsonllayer backed by SQLite, recording weighted edges between memories. Theassociation(edges)term in the strength formula draws from this graph. - Brain region routing: As fact.yml grew, it threatened to become a new junk drawer. I split it into domain-specific files (
fact_sop_dispatch.yml,fact_governance.yml,fact_tools_detail.yml) managed by a brain region manifest. Think of it as cortical specialization for your AI's memory. - Sanctum tiers: Some memories must not be casually modified. API keys, safety rules, core identity settings. I implemented a three-tier access control (public / private / sacred) where modifying sacred-tier memories requires explicit permission.
None of these extensions were planned upfront. Each emerged when a pain point crossed a threshold. The three-layer architecture is the foundation. Once the foundation is solid, anything can be built on top.
I codified the full system as an open-source Python package: Ghost in Shell, which includes the decay engine, association graph, brain region routing, deduplication, and multi-platform adapters (Claude / Codex / Copilot / Gemini).
If you are interested in seeing the full system in context, How I Automated 80% of My Daily Development Work with Claude Code shows how the memory system works alongside Skill routing, Hook gatekeepers, and other modules.
Common Design Pitfalls
Pitfall 1: Stuffing too much into the fact layer
The fact layer should only contain information that is cross-task universal and long-term stable. A specific project's API endpoint does not belong in the global fact.yml; it belongs in that project's CLAUDE.md or local config.
Pitfall 2: Never cleaning the scratchpad
If scratchpad.md only grows and never shrinks, it quickly becomes a junk drawer. Spend one minute after each task promoting the important bits to the episodic layer and clearing the rest.
Pitfall 3: Episodic entries without tags
Episodic records without tags are like a database without indexes — every lookup is a full table scan. Tag each record with at least two tags, and your future self will thank you.
FAQ
Can the three-layer memory architecture only be used with Claude Code?
No. This design pattern applies to any AI tool that supports file access. Codex CLI and other CLI-based AI tools have similar config-loading mechanisms. The differences are only in config file format and loading method; the three-layer design philosophy is universal.
Should the memory files be under Git version control?
fact.yml should be version-controlled (it is part of the system configuration). episodic.jsonl depends on the situation; if it contains sensitive decisions, add it to .gitignore. scratchpad.md typically does not need version control since it is short-lived scratch space.
Will the memory system slow the AI down?
The fact layer is usually only a few dozen to a few hundred lines, with minimal impact on token consumption. The episodic layer uses on-demand queries rather than full loading, so it does not slow down startup either. The real thing to watch is not letting the scratchpad accumulate too much content.
How is this different from ChatGPT's Memory feature?
ChatGPT's Memory is a black box. You cannot control what it remembers, how it stores memories, or when it forgets. The three-layer memory architecture is fully transparent, plain-text files. You can see every single memory entry, manually edit, delete, or migrate them. Control stays entirely in your hands.
How long does it take to build up an effective memory system?
If you use Claude Code daily, you will notice the difference in roughly two to three weeks. The fact layer can be set up on day one. The episodic layer starts gaining content after you make a few decisions and hit a few pitfalls. The key is building the habit of "spending one minute to record after each task."
Want to Go Deeper?
I put together a free AI Agent Memory System Design Blueprint that includes the complete file structure for the three-layer architecture, YAML/JSONL format specifications, the memory strength formula, and a starter template pack you can copy and use directly.
Download the Memory System Blueprint for Free
Next up: Skill Routing Engine: Letting AI Automatically Choose the Right Workflow
Found this useful?
Follow for new AI × biomedical research notes:
Or buy me a coffee to keep new content coming.
☕ Buy Me a Coffee