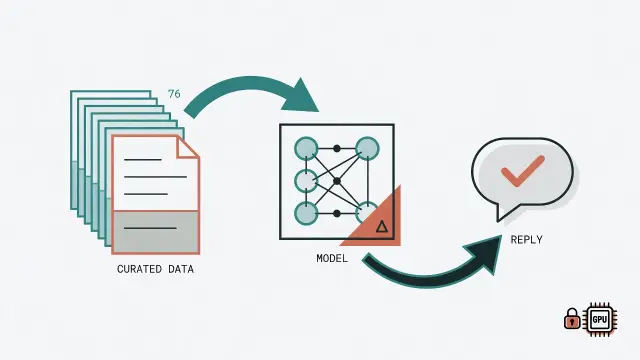
76 筆資料就能教會 AI 說你的品牌語言:Windows QLoRA 微調全攻略
用 76 筆 ChatML 訓練資料在 RTX 4060 Ti 上完成 Qwen3.5 QLoRA 微調,從環境建置到 LoRA 合併、GGUF 轉換、Ollama 部署的完整實戰紀錄,含 Windows CUDA fine-tune 五大鐵律。
用 76 筆 ChatML 訓練資料在 RTX 4060 Ti 上完成 Qwen3.5 QLoRA 微調,從環境建置到 LoRA 合併、GGUF 轉換、Ollama 部署的完整實戰紀錄,含 Windows CUDA fine-tune 五大鐵律。
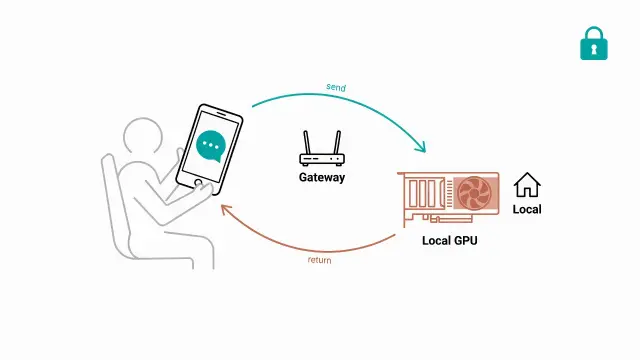
手把手帶你用 Ollama + Qwen3.5 + Hermes Gateway 在 Windows GPU 上部署 LINE Bot 客服機器人,含六個實戰踩坑與解法
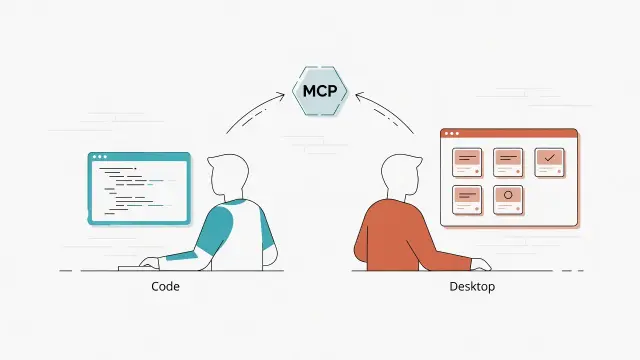
怎麼讓同一份 Kanban 看板,被任何 AI Agent 程式化管理,又能在 Claude Desktop 用漂亮的 Live artifacts 即時呈現、甚至從畫面直接改卡?拆解資料層、MCP 橋接層、呈現層的三層共治架構,附我實際做出來的晨間戰情室完整實作與安全紅線。
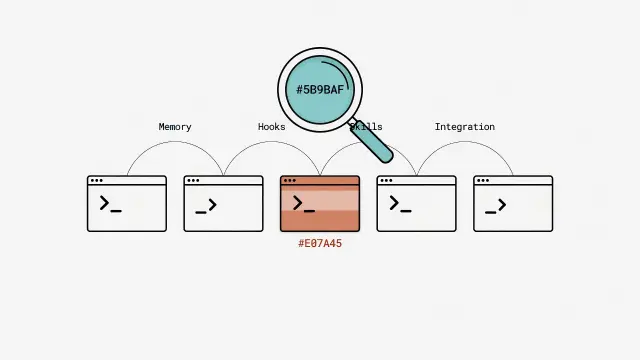
五款主流 AI Agent 工具橫向評比:記憶持久化、Hook 擴展、Skill 路由、跨平台整合全面比較,依使用情境推薦最適工具。
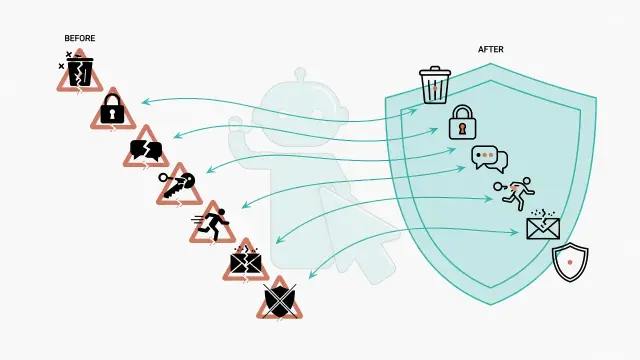
半年踩過的 7 個 AI Agent 真實踩坑記錄:從被 rm -rf 燒過、API Key 外洩到跨 session 記憶全失,每個錯誤都變成一條系統防線。
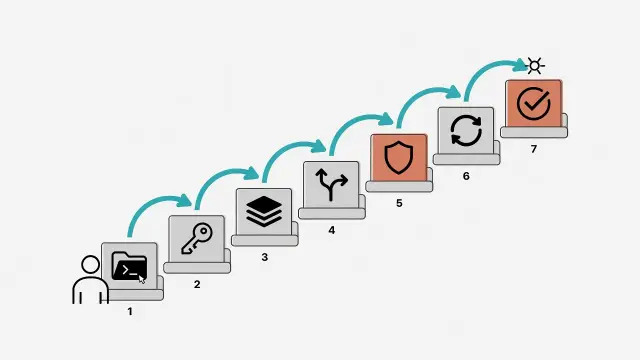
手把手帶你建立 AI Agent 系統:從房間格局規劃、開機鑰匙設定、三層大腦架構到守門員部署,七步驟完成可運作的 Agent 工作流。