TL;DR: Have you noticed that AI chatbots are responding faster than ever? It's not because they swapped in more expensive chips. Engineers developed six clever optimizations that make the same GPU do more work with less waste. This article breaks them down with six everyday analogies.
The Bottleneck
Open ChatGPT, type a question, and watch words appear on screen one by one like a typewriter. Sometimes fast, sometimes agonizingly slow. This isn't a network problem — it's how large language models fundamentally work: they can only "think" of one word at a time, and each word depends on all the ones before it.
A 70-billion-parameter model must move all 70 billion parameters from GPU memory for every single token it generates. Produce 200 tokens, and that's 200 round trips. The GPU's compute cores are actually fast — they spend most of their time waiting for data to arrive from memory.
That's the inference bottleneck. The six techniques below are what engineers built to break it.
1. KV Cache — Meeting Notes You Don't Have to Re-Read
Analogy: You're the meeting note-taker. Each time someone speaks, instead of asking everyone to repeat what they've already said, you just flip open your notebook.
How it works: In the attention mechanism, each token is transformed into three vectors: Query (the question), Key (the index label), and Value (the content). A new token uses its Query to compare against all previous Keys, identifies the most relevant ones, and retrieves their Values.
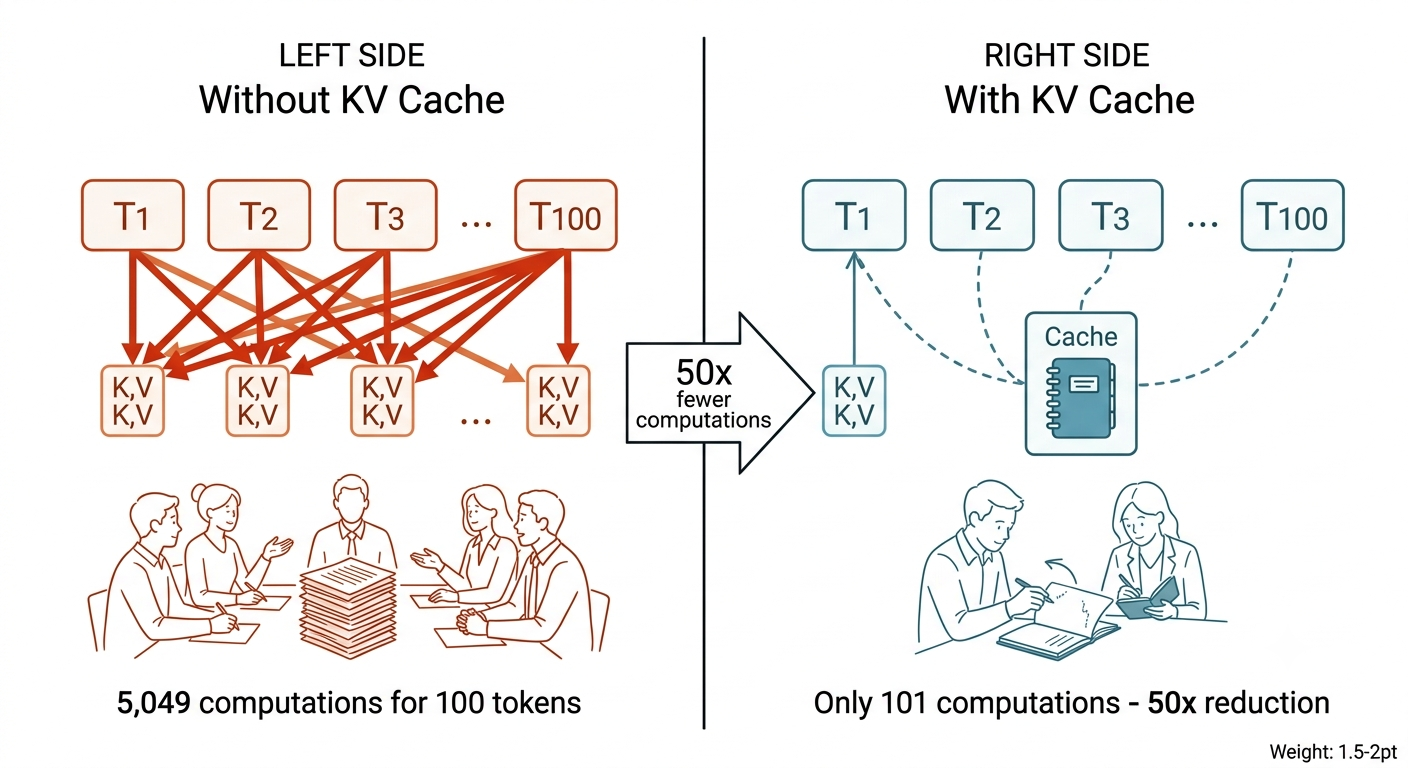
Without KV Cache, the model recomputes Keys and Values for all previous tokens at every step. KV Cache stores computed Key-Value pairs so they can be reused. Only the new token needs fresh computation.
By the numbers: Generating 100 tokens without KV Cache requires approximately 5,049 Key-Value computations. With KV Cache, just 101 — a roughly 50x reduction.
Trade-off: The cache consumes memory. Longer sequences mean larger caches. Which is exactly what the next technique addresses.
2. Paged Attention — Hotel Rooms Allocated on Demand
Analogy: A guest checks into a hotel not knowing how many nights they'll stay. The old approach reserves 30 consecutive rooms just in case. Paged Attention gives them one room, then another as needed — rooms don't have to be adjacent, and a lookup table tracks who's in which room.
How it works: Traditional KV Cache pre-allocates a contiguous memory block assuming maximum output length (say, 2,048 tokens). If the actual response is 50 tokens, 1,998 slots are wasted. Paged Attention borrows from OS virtual memory management: it slices the KV Cache into fixed-size blocks (e.g., 4 tokens each), allocates on demand, and uses a block table to track locations.
Impact: Internal waste is nearly eliminated. External fragmentation disappears. The same GPU can serve dramatically more concurrent users. Multiple requests with identical prefixes can even share KV Cache blocks.
3. Flash Attention — Reading at a Small Desk
Analogy: The standard approach is like hauling every book in the library onto one enormous table. Flash Attention brings just one chapter to your small desk, reads it, takes notes, returns it, and fetches the next. You never need the giant table.
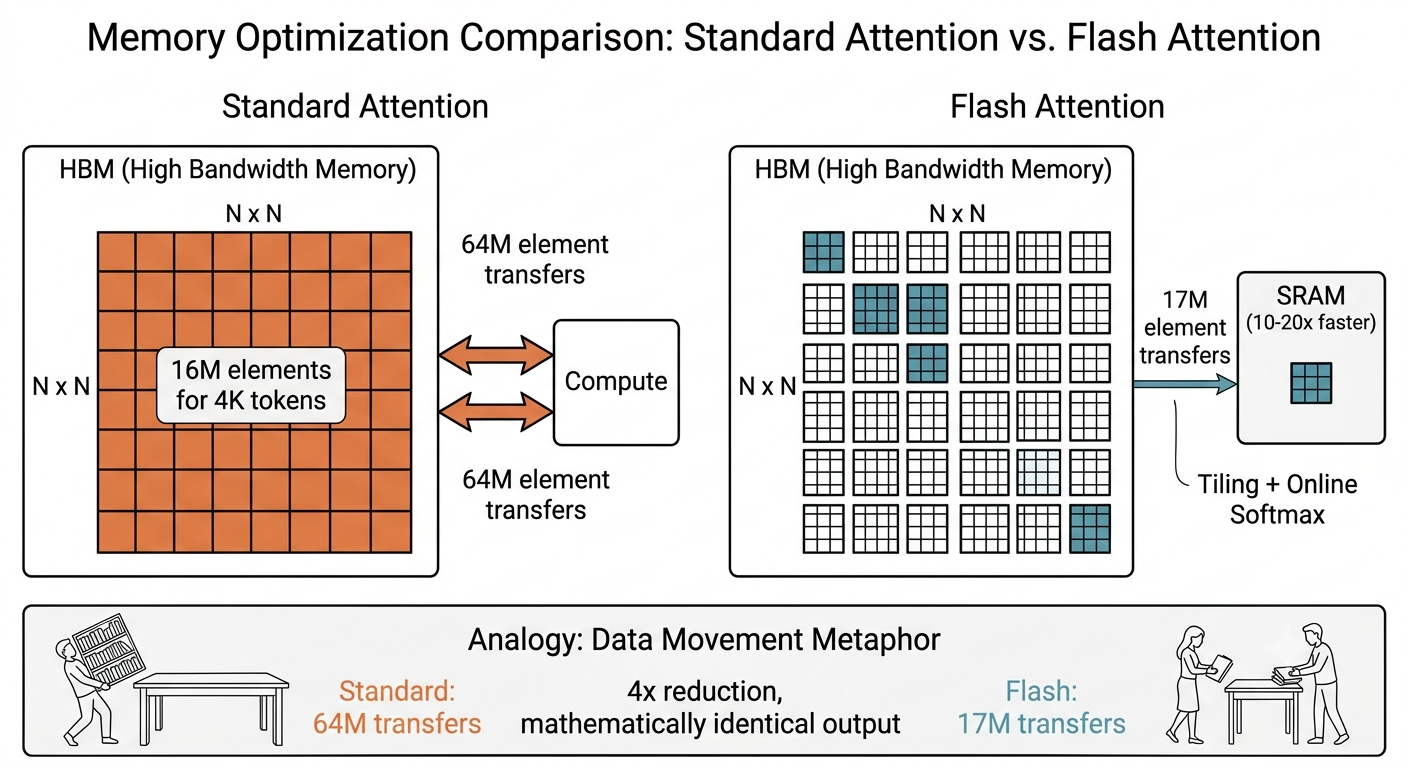
How it works: GPUs have two memory tiers. HBM is large but slow (the distant library). SRAM is tiny but 10-20x faster (the small desk). Standard attention creates an N x N matrix in HBM (4,000 tokens = 16 million elements), shuttled back and forth four times — roughly 64 million element transfers.
Flash Attention avoids this massive matrix with two tricks: Tiling (processing Q, K, V in small blocks loaded into SRAM) and Online Softmax (computing softmax incrementally without seeing the full row).
By the numbers: For 4,000 tokens, Flash Attention moves about 17 million elements — one quarter of the standard approach. The gap widens with longer sequences. Flash Attention 2 and 3 push performance further with reduced non-matmul operations and hardware-specific async transfers.
Crucially: Flash Attention produces mathematically identical output to standard attention. Zero approximation, zero quality loss.
4. Grouped Query Attention (GQA) — Detectives Sharing Case Notes
Analogy: Eight detectives investigating the same case. Traditional Multi-Head Attention gives each detective their own evidence notebook — best quality, but expensive. GQA groups the eight into two teams of four, each team sharing one notebook. Notebook count drops from 8 to 2, while retaining two distinct perspectives.
How it works: In MHA, each attention head maintains its own Query, Key, and Value. GQA lets multiple heads share the same Key-Value pairs while keeping independent Queries.
By the numbers: LLaMA 2 70B has 64 Query heads grouped into 8 KV groups — KV Cache shrinks to 1/8th. Existing MHA models can be converted to GQA by averaging same-group Key/Value weights and fine-tuning for roughly 5% of original training, with near-zero quality degradation.
5. Continuous Batching — Rideshare Taxis That Never Run Empty
Analogy: A 4-seat taxi. Static Batching picks up 4 passengers at once; if one arrives at their destination in 5 minutes, the seat stays empty until the last passenger finishes. Continuous Batching lets a waiting passenger hop in immediately when someone exits — seats stay full.
How it works: LLM servers batch multiple requests for joint GPU processing. Static Batching waits for the entire batch to complete. Continuous Batching checks at every decode step: finished requests are ejected, queued requests fill the gaps.
By the numbers: Given 100 requests (50 short at 20 tokens, 50 long at 200 tokens), Static Batching takes 250 seconds at 44 tokens/sec throughput. Continuous Batching finishes in 137.5 seconds at 80 tokens/sec — 1.8x faster. Combined with Paged Attention, vLLM benchmarks show throughput gains exceeding 20x over naive approaches.
6. Speculative Decoding — Intern Drafts, Manager Reviews in Bulk
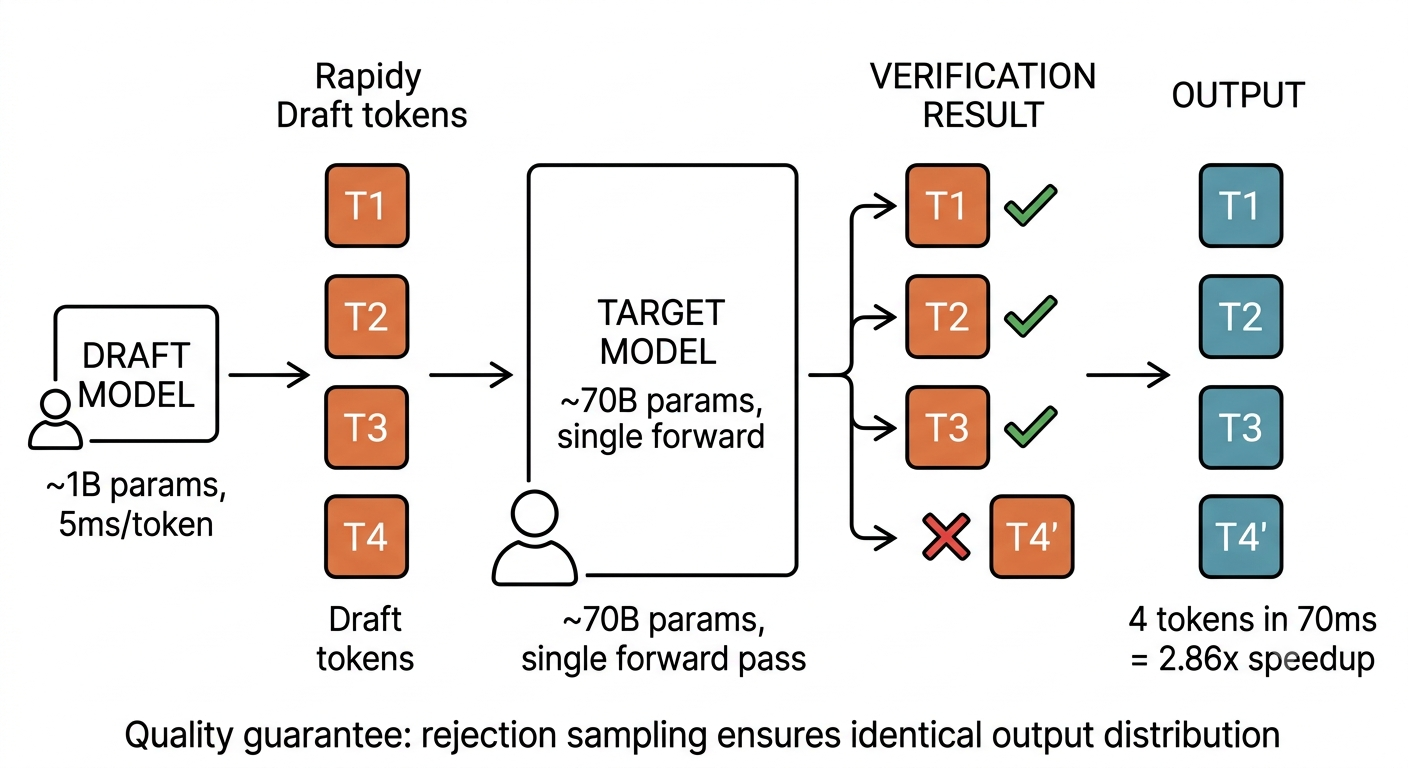
Analogy: A senior engineer writes meticulous but slow code. An intern sits beside them, quickly drafting 4-5 lines. The senior reviews them all at once: correct lines stay, the first wrong line gets replaced, everything after is discarded. Most of the time, the intern's first few lines are right, saving the senior the time of writing line by line.
How it works: A small "draft model" (~1B parameters) rapidly generates 4 tokens. The large "target model" (~70B parameters) verifies all 4 in a single forward pass. Accepted tokens are kept; at the first rejection, the target model's choice replaces it and subsequent tokens are discarded.
Through rejection sampling, the final output distribution is mathematically identical to using the target model alone. Zero quality loss.
By the numbers: Target model at 50 ms/token, draft model at 5 ms/token. One round costs 4 x 5 + 50 = 70 ms. Best case (all 4 accepted): 5 tokens in 70 ms, a 3.57x speedup. Average case (3 accepted): 4 tokens in 70 ms, a 2.86x speedup. A 200-token response shrinks from 10 seconds to 3.5.
The Latest: MTP and Technique Stacking
In May 2026, Google released a Multi-Token Prediction (MTP) drafter for Gemma 4. Unlike traditional Speculative Decoding, the MTP drafter isn't a separate model — it's a lightweight module embedded during training that learns to predict multiple future tokens simultaneously. At inference time, it acts as a built-in drafter with no additional model loading required. DeepSeek-V3 reported approximately 1.8x generation speedup with a similar MTP architecture. Google claims up to 3x acceleration, released under Apache 2.0.
In practice, a modern inference engine like vLLM runs KV Cache + Paged Attention + Flash Attention + GQA + Continuous Batching simultaneously, optionally adding Speculative Decoding. Each layer targets a different bottleneck. Stacked together, the gains multiply.
Real-World Impact
Next time you open ChatGPT, Claude, or Gemini and notice faster responses, these are the techniques at work. No bigger GPUs, no changes to model math, no quality sacrifice. They simply ensure that every inch of memory bandwidth and every compute core on the chip stops being wasted on redundant transfers and idle cycles.
These optimizations aren't free, however. KV Cache and Paged Attention consume GPU memory — at context lengths beyond 128K tokens, the cache alone can saturate an entire GPU's VRAM. Flash Attention's tiling strategy shows inconsistent speedups across hardware architectures, with AMD GPU support still trailing NVIDIA by roughly half a generation. Speculative Decoding's acceleration depends heavily on draft model hit rates, which drop for high-creativity tasks like poetry or brainstorming.
For researchers, these techniques mean longer context windows, more concurrent requests, and larger models on the same consumer GPU. For everyday users, it's the complete engineering story behind five simple words: "AI got faster."
References
- Amit Shekhar, "KV Cache in LLMs," Outcome School, 2026-03-27.
- Amit Shekhar, "Paged Attention in LLMs," Outcome School, 2026-03-29.
- Amit Shekhar, "Decoding Flash Attention in LLMs," Outcome School, 2026-04-11.
- Amit Shekhar, "Grouped Query Attention," Outcome School, 2026-04-22.
- Amit Shekhar, "Continuous Batching in LLMs," Outcome School, 2026-05-11.
- Amit Shekhar, "Speculative Decoding," Outcome School, 2026-05-06.
- @googleaidevs, "Speed up your Gemma 4 workflows by up to 3x with Multi-Token Prediction (MTP) drafters," X post, 2026-05-06.
Found this useful?
Follow for new AI × biomedical research notes:
Or buy me a coffee to keep new content coming.
☕ Buy Me a Coffee