導讀:你有沒有注意到,AI 聊天機器人的回應速度正在變快?從逐字龜速到幾乎即時,背後不是換了更貴的晶片,而是工程師用了六招聰明的「偷吃步」。這篇文章用六個生活比喻,帶你一次看懂。
開篇鉤子
你打開 ChatGPT,輸入一個問題,看著螢幕上的文字像打字機一樣一個字一個字蹦出來。有時候快、有時候慢,有時候等到你懷疑它是不是當機了。這不是你的網路問題,而是大型語言模型(LLM)天生的運作方式:它每次只能「想」出一個字,想完一個才能想下一個。
一個 700 億參數的模型,每產出一個字,就得把 700 億個參數從 GPU 記憶體裡搬一遍。產出 200 個字,就搬 200 遍。GPU 的運算核心其實很快,大部分時間都在等資料從記憶體搬過來。
這就是 LLM 推論的瓶頸。而接下來要介紹的六項技術,正是工程師們為了打破這個瓶頸所發展出來的解法。
1. 為什麼 AI 那麼慢?先搞懂它怎麼「想」
LLM 產生文字的方式叫做 autoregressive decoding:一次只生一個 token(可以想成一個字或一個詞),生完之後把它接到前面的句子後面,再根據整段句子預測下一個 token。
問題出在「根據整段句子」這件事。每預測一個新字,模型都要重新審視前面所有的字。如果已經生了 100 個字,要預測第 101 個字時,模型得對前面 100 個字全部重新計算一次注意力(attention)。這就像一場會議裡,每來一個新人發言,所有人都要從頭把會議紀錄重唸一遍。
這完全不合理。所以,第一個加速技術登場了。
2. 六大加速技術逐一拆解
技術一:KV Cache -- 會議筆記,不用每次重聽
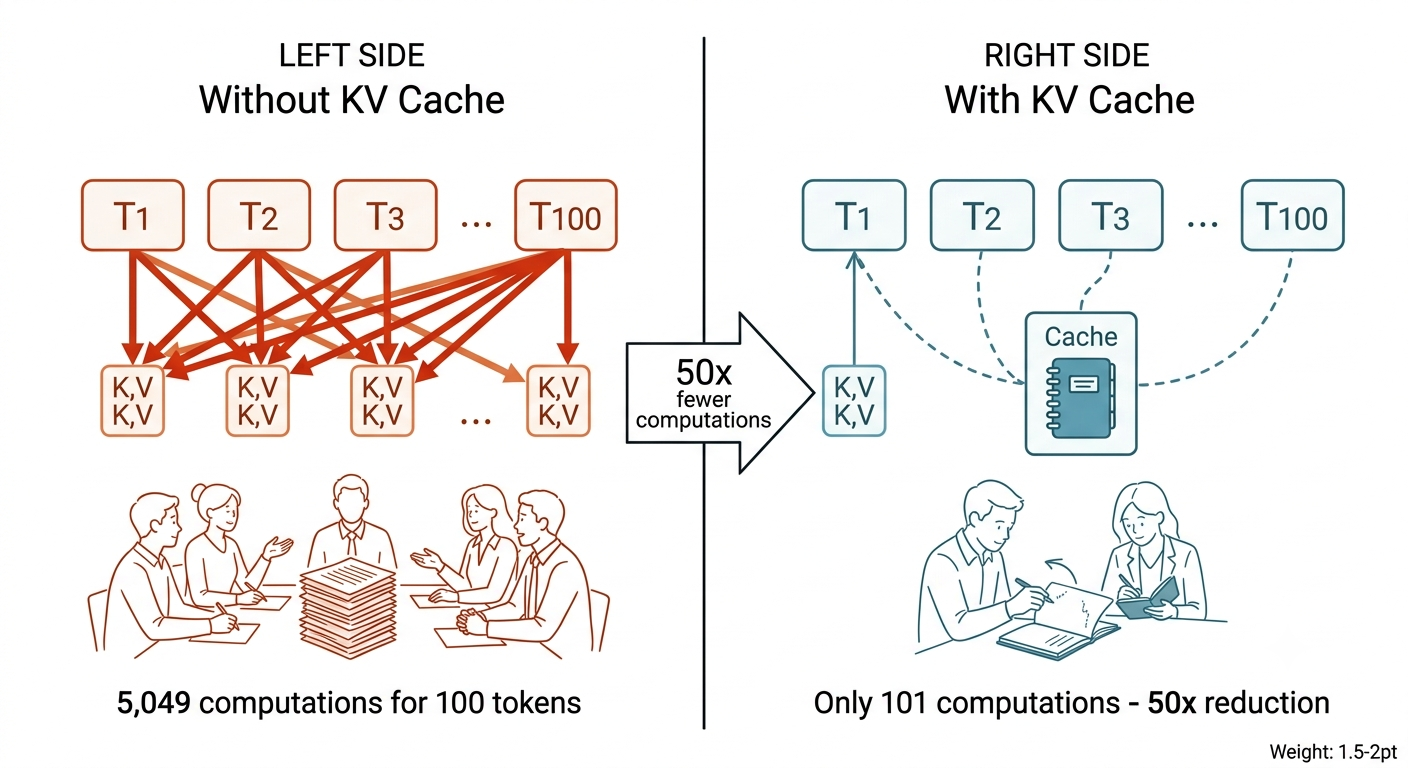
比喻:你是會議記錄員。每次有人發言,你不用要求所有人把之前說過的話再講一遍,你只要翻開筆記本就好。
原理:在注意力機制裡,每個 token 會被轉換成三個向量:Query(問題)、Key(索引標籤)、Value(內容)。新 token 用自己的 Query 去比對所有舊 token 的 Key,找出哪些舊 token 比較相關,然後取用它們的 Value。
沒有 KV Cache 的情況下,模型每生一個新字,就要重新計算前面所有 token 的 Key 和 Value。KV Cache 的做法是:算過的 Key 和 Value 存起來,下一步直接取用,只需要替新 token 算一組就好。
具體數字:生成一段 100 個 token 的文字,沒有 KV Cache 需要約 5,049 次 Key-Value 計算;有了 KV Cache 只需要 101 次,運算量縮減將近 50 倍。
代價:快取會吃記憶體。序列越長,快取越大。而這個問題,正好由下一個技術來解決。
技術二:Paged Attention -- 旅館按需給房間
比喻:一間旅館來了一位客人,不知道會住幾晚。傳統做法是直接預留 30 間連續房間以防萬一;Paged Attention 的做法是先給 1 間,需要再給,不必連號,旅館用一張對照表記錄哪些房間屬於哪位客人。
原理:傳統的 KV Cache 會為每個請求預留一大塊連續記憶體,假設最長可能產出 2,048 個 token。但實際回應可能只有 50 個 token,剩下 1,998 個位置全部浪費。
Paged Attention 借鏡作業系統的分頁記憶體管理:把 KV Cache 切成固定大小的小區塊(例如每塊 4 個 token),按需分配,區塊不必連續,靠 block table 記錄位置。
效果:內部浪費幾乎消除(只有最後一個區塊可能沒填滿),外部碎片也不再是問題。同一張 GPU 上能同時服務的使用者數量大幅增加。多個請求如果問了相同的問題,甚至可以共享同一批輸入 token 的 KV Cache 區塊,再多省一筆記憶體。
技術三:Flash Attention -- 在小桌子上讀書
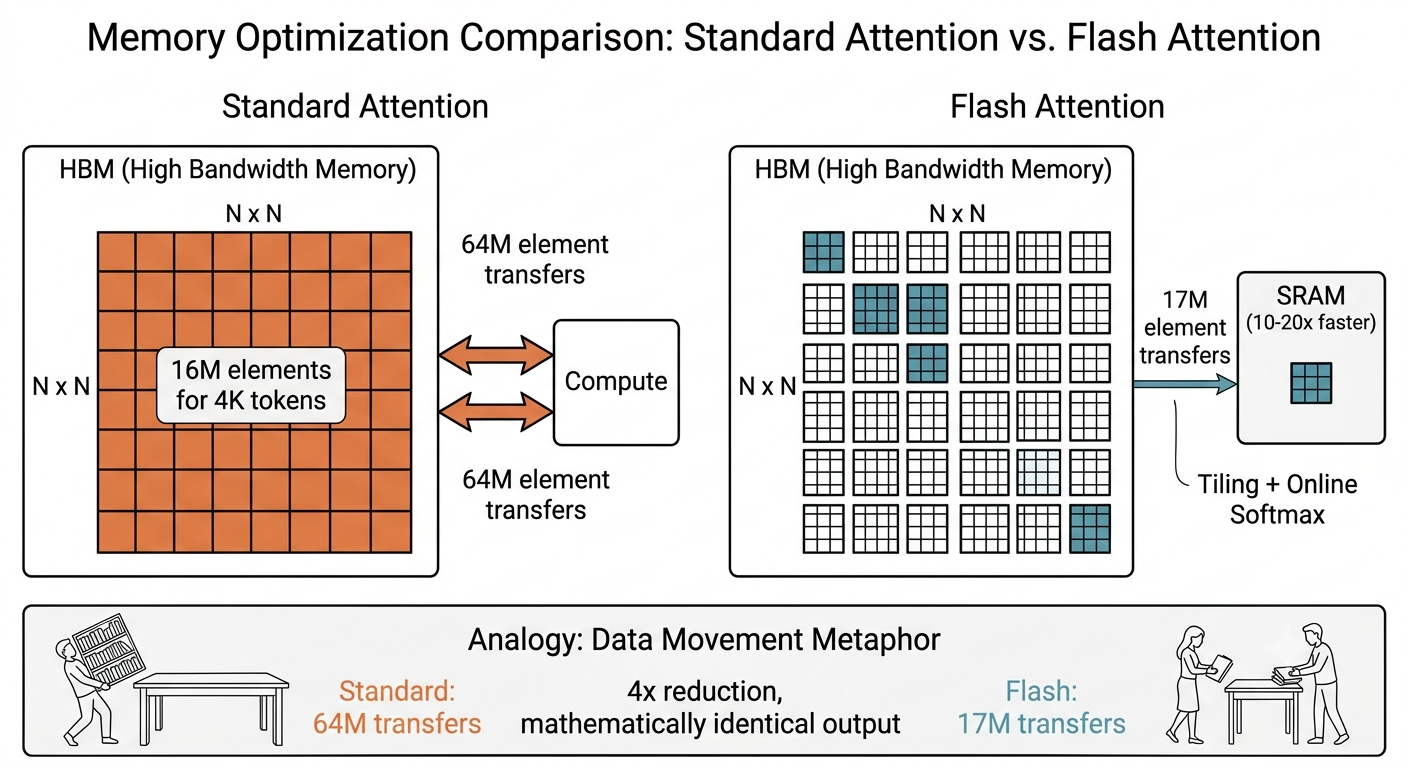
比喻:標準做法像是把整座圖書館的書全搬到一張巨大桌子上攤開來讀。Flash Attention 的做法是只帶一小章到你面前的小桌子,讀完做筆記、還回去,再帶下一章。你永遠不需要那張巨大桌子。
原理:GPU 有兩種記憶體。HBM 很大但慢(好比遠處的圖書館),SRAM 很小但快上 10 到 20 倍(好比面前的小桌子)。標準注意力會在 HBM 中產生一個 N x N 的巨大矩陣(4,000 個 token 就是 1,600 萬個元素),這個矩陣被來回搬運 4 次,總搬運量約 6,400 萬個元素。
Flash Attention 用兩個技巧避開這個巨大矩陣:
- Tiling:把 Q、K、V 切成小區塊(例如 256 個 token 一塊),每次只載入一小塊到 SRAM 做運算。
- Online Softmax:用一個持續更新的最大值與累加和,讓 softmax 可以分批計算而不需要看到整列。
具體數字:同樣 4,000 個 token,Flash Attention 的搬運量約 1,700 萬個元素,是標準做法的四分之一。序列越長差距越大。Flash Attention 2 砍掉多餘的非矩陣乘法運算,速度再快約 2 倍。Flash Attention 3 則針對 NVIDIA H100/H200 的硬體特性做非同步搬運,讓 GPU 幾乎零等待。
最重要的是:Flash Attention 的輸出結果與標準注意力完全相同,沒有任何近似或品質損失。
技術四:Grouped Query Attention(GQA)-- 偵探小組共享線索筆記
比喻:8 個偵探調查同一個案件。傳統的 Multi-Head Attention(MHA)讓每個偵探各自蒐證、各寫各的筆記本,品質最好但筆記本開銷很大。GQA 把 8 個偵探分成 2 組,每組 4 人共用一本線索筆記。筆記本數量從 8 本減到 2 本,但仍保留兩套不同觀點。
原理:MHA 中每個注意力頭(head)各有自己的 Query、Key、Value。GQA 讓多個 head 共享同一組 Key 和 Value,只保留各自獨立的 Query。
具體數字:LLaMA 2 70B 有 64 個 Query head,分成 8 組共享 KV,KV Cache 縮小為原來的 1/8。Mistral 7B 同樣採用 GQA,32 個 Query head 配 8 組 KV。既有的 MHA 模型甚至不用從頭訓練,只要把同組 head 的 Key/Value 權重平均、再微調約 5% 的原始訓練量就能轉換成 GQA,品質幾乎不變。
技術五:Continuous Batching -- 共乘計程車,有人下車立刻接新客
比喻:一台 4 人座計程車。靜態批次(Static Batching)是 4 位乘客同時上車,就算有人 5 分鐘後到站下車了,那個座位也空著,等最後一位乘客到站才收工、才接新一批。Continuous Batching 是有人下車,路邊等候的乘客立刻遞補,座位永遠滿載。
原理:LLM 伺服器把多個使用者的請求打包成一個 batch 丟給 GPU 一起算。Static Batching 要等整批跑完才接新批;Continuous Batching 以「每一步 decode」為單位檢查:誰做完了就送走,誰在排隊就補進來。
具體數字:假設 100 個請求(50 個短回應 20 token、50 個長回應 200 token),Static Batching 需要 250 秒,吞吐量 44 tokens/sec。Continuous Batching 只需 137.5 秒,吞吐量 80 tokens/sec,快了 1.8 倍。搭配 Paged Attention 使用時,vLLM 實測吞吐量可達到未最佳化做法的 20 倍以上。
技術六:Speculative Decoding -- 實習生先寫初稿,主管一次審批
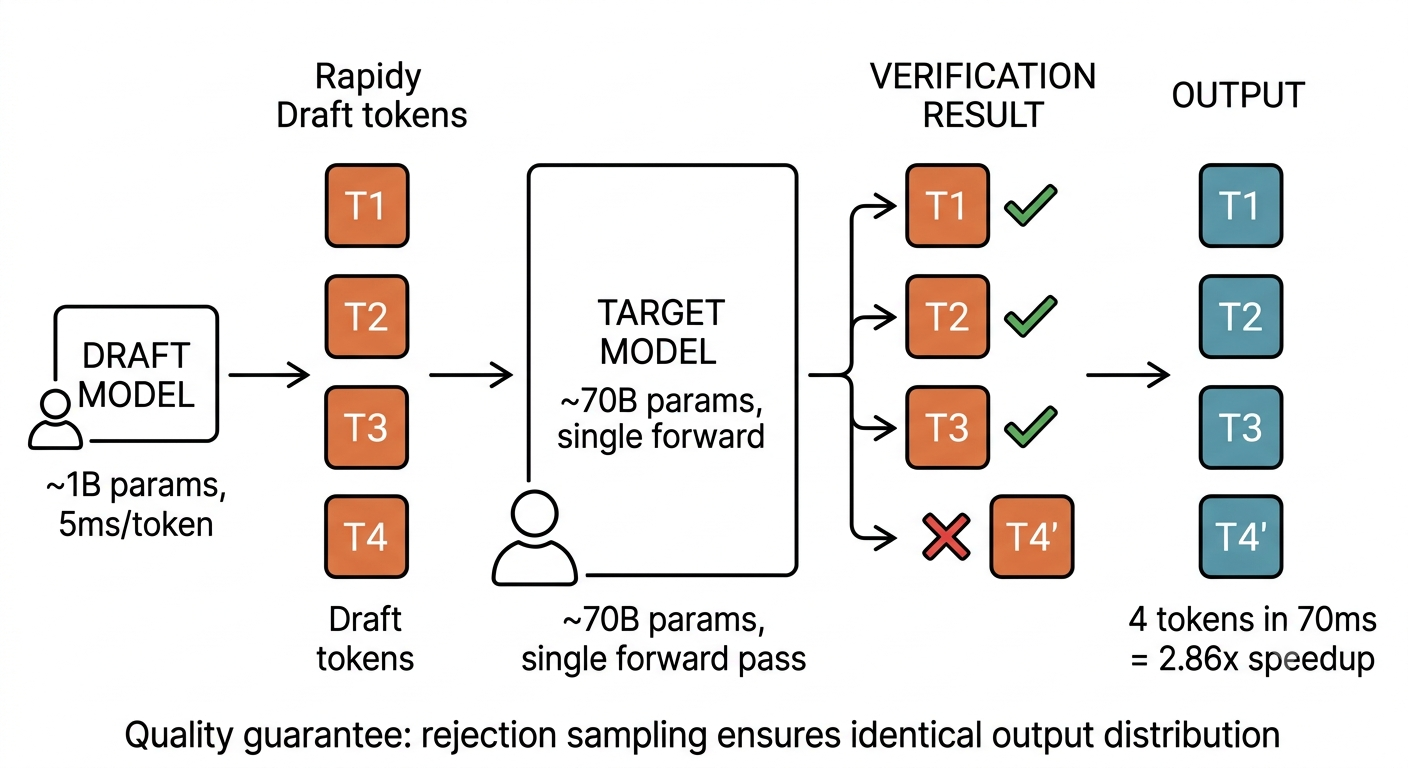
比喻:一位資深工程師寫程式很嚴謹但很慢。旁邊安排一位實習生,先快速寫出 4、5 行草稿,資深工程師一口氣審完:對的留下、第一行錯的改掉、後面的丟掉。大部分時候實習生前幾行都寫對了,資深工程師省下逐行撰寫的時間。
原理:準備一個小型的「草稿模型」(draft model,約 10 億參數)和一個大型的「目標模型」(target model,約 700 億參數)。草稿模型快速連續產出 4 個 token,目標模型在一次 forward pass 中同時驗證這 4 個 token。驗證通過的直接保留,遇到第一個不通過的就用目標模型的選擇取代,後面的丟棄。
透過 rejection sampling,最終輸出的機率分布與純用目標模型完全相同,品質零損失。
具體數字:
- 目標模型每個 token 耗時 50 ms,草稿模型 5 ms/token
- 一輪 Speculative Decoding 成本:4 x 5 ms + 50 ms = 70 ms
- 最佳情況(4 個全過):70 ms 產出 5 個 token,加速 3.57 倍
- 平均情況(3 個通過):70 ms 產出 4 個 token,加速 2.86 倍
- 產出 200 token 的回應:從 10 秒縮短到 3.5 秒
3. 最新趨勢:MTP 與技術的搭配組合
2026 年 5 月,Google 為 Gemma 4 發布了 Multi-Token Prediction(MTP)drafter。與傳統 Speculative Decoding 不同的是,MTP drafter 不是獨立的第二個模型,而是在訓練階段就嵌入主模型的一個輕量模組,學習同時預測多個未來 token。推論時,這個模組直接充當內建草稿員,不需要額外載入第二個模型。
DeepSeek-V3 也採用了類似的 MTP 架構,回報約 1.8 倍的生成加速。Google 宣稱 Gemma 4 MTP drafter 可帶來最高 3 倍加速,且以 Apache 2.0 開源授權釋出。
這六項技術並非各自獨立運作。實務上,一個現代推論引擎(如 vLLM)會同時啟用 KV Cache + Paged Attention + Flash Attention + GQA + Continuous Batching,再視情況搭配 Speculative Decoding。每一層技術解決不同的瓶頸:KV Cache 省重複運算、Paged Attention 省記憶體碎片、Flash Attention 省資料搬運、GQA 省快取空間、Continuous Batching 省 GPU 閒置時間、Speculative Decoding 省逐字等待。層層疊加,效果才能倍數放大。
現實連結
你下次打開 ChatGPT、Claude 或 Gemini 時,看到回應速度比半年前快了不少,背後就是這些技術在運作。它們沒有換更大的 GPU,沒有改變模型的數學運算,也沒有犧牲回答品質。它們做的事情,就是讓同一顆晶片上的每一寸記憶體頻寬和每一個運算核心,都不再浪費在重複的搬運與等待上。
不過,這些加速並非毫無代價。KV Cache 和 Paged Attention 都會吃掉 GPU 記憶體,當上下文長度超過 128K token 時,快取本身可能佔滿整張顯卡的 VRAM。Flash Attention 的 tiling 策略在某些硬體架構上的加速幅度也不一致,AMD GPU 的支援至今仍落後 NVIDIA 半代以上。Speculative Decoding 的加速效果高度依賴草稿模型的命中率,當任務需要高創意性輸出(如詩歌、brainstorming)時,草稿命中率會下降,加速比也跟著縮水。
對研究者來說,這些技術意味著你可以在同一張消費級顯卡上跑更長的上下文視窗、服務更多併發請求、或是用更大的模型做實驗。對一般使用者來說,它就是「AI 變快了」這五個字背後的全部工程。
結語
LLM 推論加速不是一個技術,而是六個齒輪咬合在一起的系統工程。從快取到分頁、從記憶體分層到注意力分組、從排程最佳化到投機解碼,每一項都在回答同一個問題:怎麼讓 GPU 別閒著?
而 MTP drafter 的出現,預告了下一個方向:不再需要另外養一個草稿模型,直接讓主模型在訓練時就學會「一次想好幾步」。未來的 LLM 不只會更聰明,也會更快。
常見問題
Q:這六種技術會改變模型的輸出品質嗎?
不會。KV Cache、Flash Attention、GQA、Paged Attention、Continuous Batching 都不改變注意力的數學運算,輸出結果完全相同。Speculative Decoding 則透過 rejection sampling 數學保證,最終產出的機率分布與單獨使用大模型一模一樣。
Q:一般使用者能直接受惠嗎?
可以。這些技術已內建於 vLLM、TensorRT-LLM 等主流推論引擎,ChatGPT、Claude、Gemini 等服務的後端都有採用。使用者不需要做任何設定,回應速度的提升是自動發生的。
Q:Speculative Decoding 需要額外的 GPU 記憶體嗎?
需要。草稿模型會佔用一部分 GPU 記憶體。但因為草稿模型通常只有 10 億參數左右,相對於 700 億參數的主模型,額外開銷很小,換來的 2 到 3 倍加速非常划算。
References
- Amit Shekhar, "KV Cache in LLMs," Outcome School, 2026-03-27.
- Amit Shekhar, "Paged Attention in LLMs," Outcome School, 2026-03-29.
- Amit Shekhar, "Decoding Flash Attention in LLMs," Outcome School, 2026-04-11.
- Amit Shekhar, "Grouped Query Attention," Outcome School, 2026-04-22.
- Amit Shekhar, "Continuous Batching in LLMs," Outcome School, 2026-05-11.
- Amit Shekhar, "Speculative Decoding," Outcome School, 2026-05-06.
- @googleaidevs, "Speed up your Gemma 4 workflows by up to 3x with Multi-Token Prediction (MTP) drafters," X post, 2026-05-06.
常見問題
這六種技術會改變模型的輸出品質嗎?
不會。KV Cache、Flash Attention、GQA、Paged Attention、Continuous Batching 都不改變注意力的數學運算,輸出結果完全相同。Speculative Decoding 則透過 rejection sampling 數學保證,最終產出的機率分布與單獨使用大模型一模一樣。
一般使用者能直接受惠嗎?
可以。這些技術已內建於 vLLM、TensorRT-LLM 等主流推論引擎,ChatGPT、Claude、Gemini 等服務的後端都有採用。使用者不需要做任何設定,回應速度的提升是自動發生的。
Speculative Decoding 需要額外的 GPU 記憶體嗎?
需要。草稿模型會佔用一部分 GPU 記憶體。但因為草稿模型通常只有 10 億參數左右,相對於 700 億參數的主模型,額外開銷很小,換來的 2 到 3 倍加速非常划算。