
TL;DR
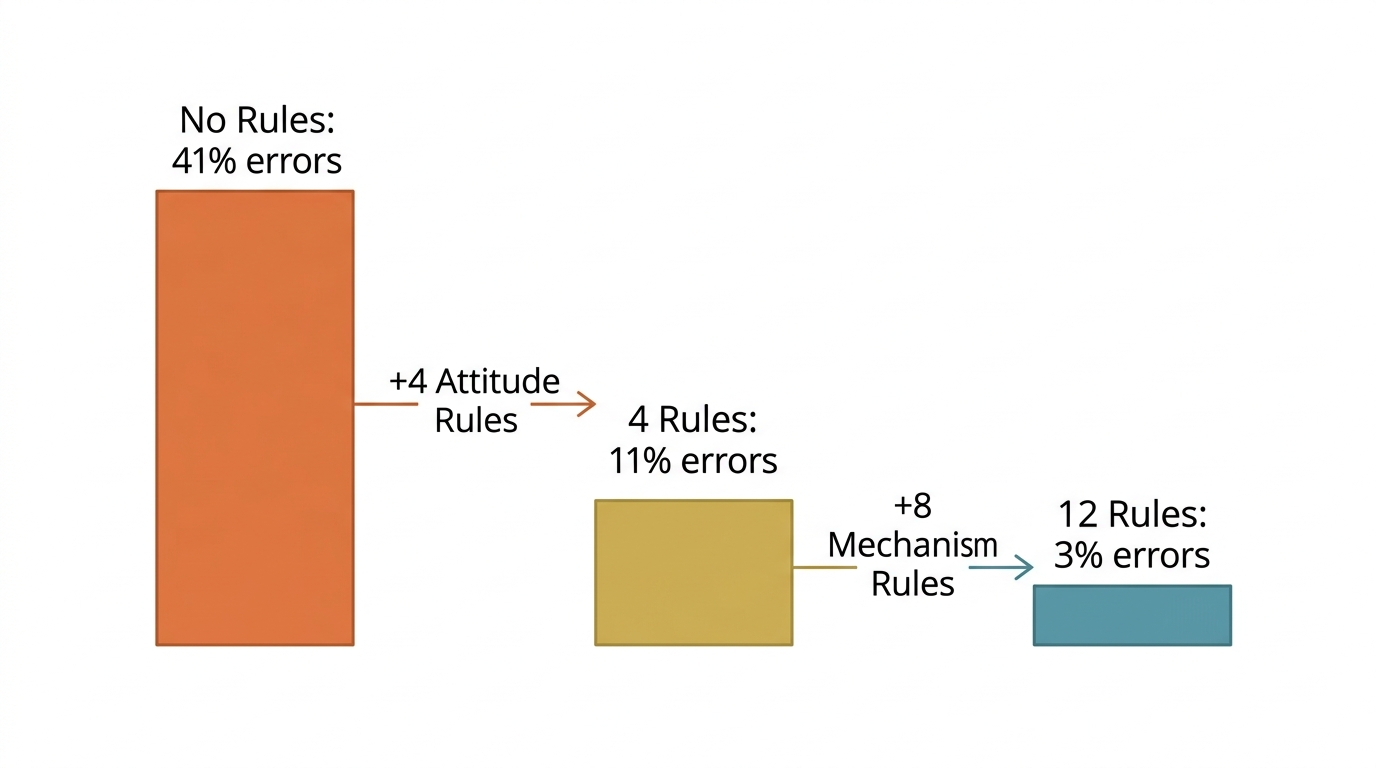
Your AI coding assistant keeps botching your requests? The problem likely isn't the AI -- it's that you never gave it a proper rulebook. Karpathy demonstrated that 4 well-crafted rules in CLAUDE.md slashed error rates from 41% to 11%. After 6 weeks of testing across 30 codebases, 8 additional rules pushed that number down to 3%.
Your AI Isn't Dumb -- It's Lawless
Most people's first experience with an AI coding assistant goes something like this: you ask it to change one line, and it rewrites the entire file. You ask it to fix a minor bug, and it "helpfully" modifies a dozen unrelated things.
The issue is structural. Imagine hiring an intern without telling them the company's coding style, project conventions, or which files are off-limits. They're not incompetent -- they simply don't know the rules.
CLAUDE.md is that rulebook. Think of it as a constitution for AI behavior. And the data backs up just how much it matters.
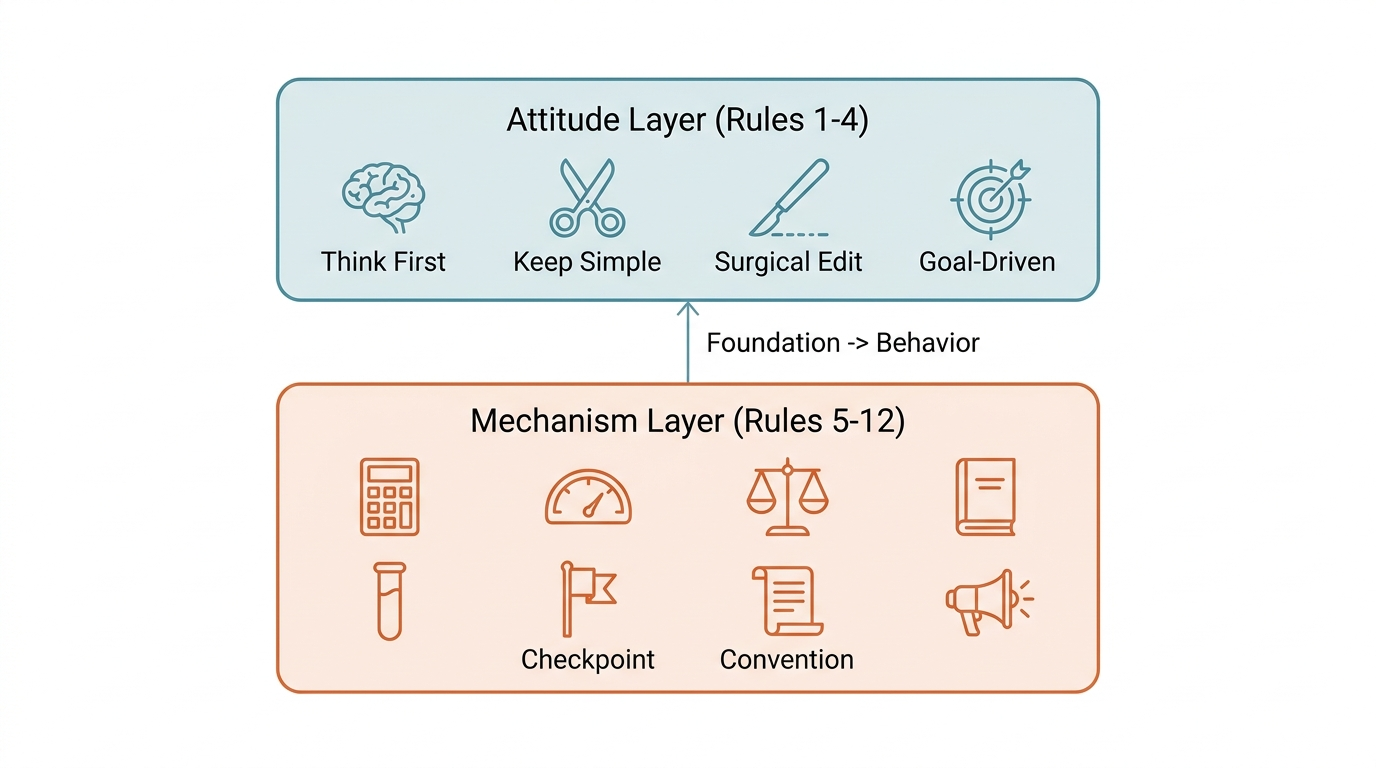
The Original 4: Attitude Rules
Karpathy's initial framework defines how the AI should approach work:
- Think before you act. Analyze the problem before generating code.
- Prefer simplicity. If you can change one line, don't change ten.
- Surgical edits only. Touch only what needs touching. Leave everything else alone.
- Stay goal-driven. Every change must map to a clear objective. No "while I'm at it" modifications.
These sound obvious, but AI models are trained to demonstrate capability by doing more. You have to explicitly tell them: less is more.
With just these 4 rules, error rates dropped from 41% to 11%.
The Next 8: Mechanism Rules
The additional rules emerged from 6 weeks of real-world testing across 30 different codebases. They address deeper behavioral failure modes:
- Models judge; code computes. Math, exact matching, deterministic logic -- delegate these to code, not the model's probabilistic reasoning.
- Hard token budget. Cap response length to prevent the AI from writing a dissertation when you asked for a patch.
- Conflicts: pick a side. When two rules contradict, choose one. Never average them into mush.
- Read before you write. Before modifying any file, read its current contents in full.
- Test for intent. After making changes, run tests to verify the result matches the original design purpose.
- Checkpoints for multi-step tasks. Break complex work into segments, reporting back after each one.
- Follow existing conventions. If the project already has a style, match it.
- Fail loudly. When something can't be done, say so immediately. Never guess silently.
These 8 rules brought the error rate from 11% down to 3%.
The 200-Line Cliff
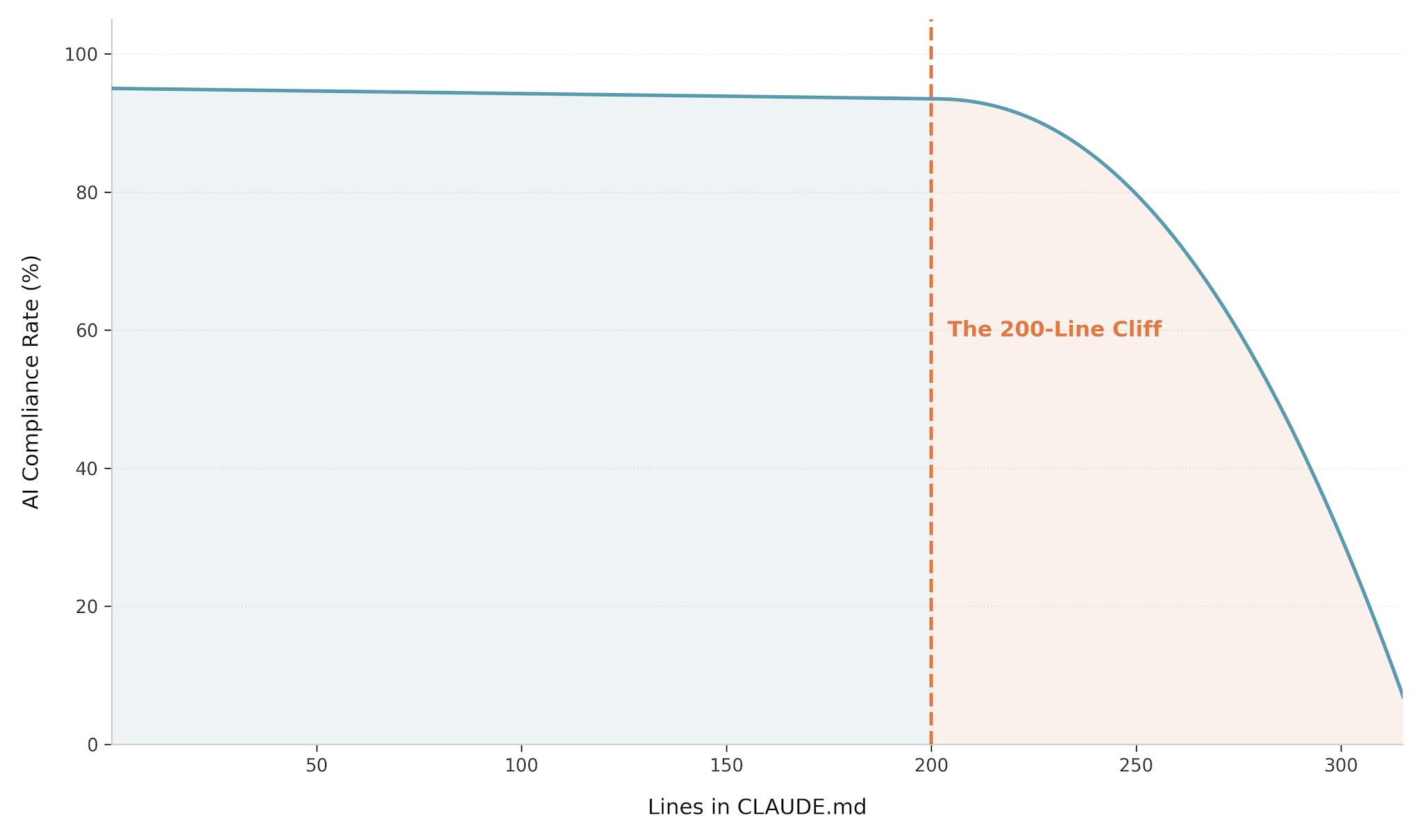
Here's the trap: after seeing these results, many developers start stuffing their CLAUDE.md with dozens of additional rules. This backfires spectacularly.
Testing showed that once CLAUDE.md exceeds 200 lines, compliance rates drop sharply. The model's attention gets diluted -- it literally can't prioritize when everything is "important."
Two related findings are worth noting:
- Examples are expensive. They consume more tokens than rules and tend to cause overfitting. The AI handles the exact scenario in your example beautifully but chokes on anything slightly different.
- Role-playing doesn't work. Telling Claude "you are a senior engineer" has zero measurable effect on behavior. Specific behavioral instructions are what actually change outputs.
For long-term projects, the solution is nested CLAUDE.md files: a top-level "constitutional" file for universal rules, and folder-specific files for task-level instructions. This keeps any single file under the 200-line threshold while maintaining consistency.
3 Takeaways for Non-Engineers
Even if you've never touched Claude Code, the framework behind these 12 rules applies to any AI interaction:
Write rules, not wishes. "Help me write a good article" is a wish. "Use formal English, stay under 800 words, start each section with a subheading" is a rule.
Fewer, sharper instructions beat longer lists. Pick your top 5 rules and rank them. AI, like people, selectively forgets when overloaded.
Demand loud failure. Add "If you're unsure about anything, tell me directly instead of guessing" to your prompts. This single instruction prevents a surprising number of silent errors.
AI isn't a mind reader. It's a collaborator that needs clear rules. The sharper your rulebook, the more reliable its output.
Based on Karpathy's original rules and community testing across 30 codebases over 6 weeks.
Found this useful?
Follow for new AI × biomedical research notes:
Or buy me a coffee to keep new content coming.
☕ Buy Me a Coffee