
Right now, somewhere on a server rack, a Transformer model is making a choice. Out of the last 100,000 tokens in a conversation, which ones deserve a second look? The mechanism behind that choice is called Attention. And there isn't just one kind. Between 2017 and 2026, at least 13 major variants have emerged, each placing a different bet on the speed-memory-quality triangle.
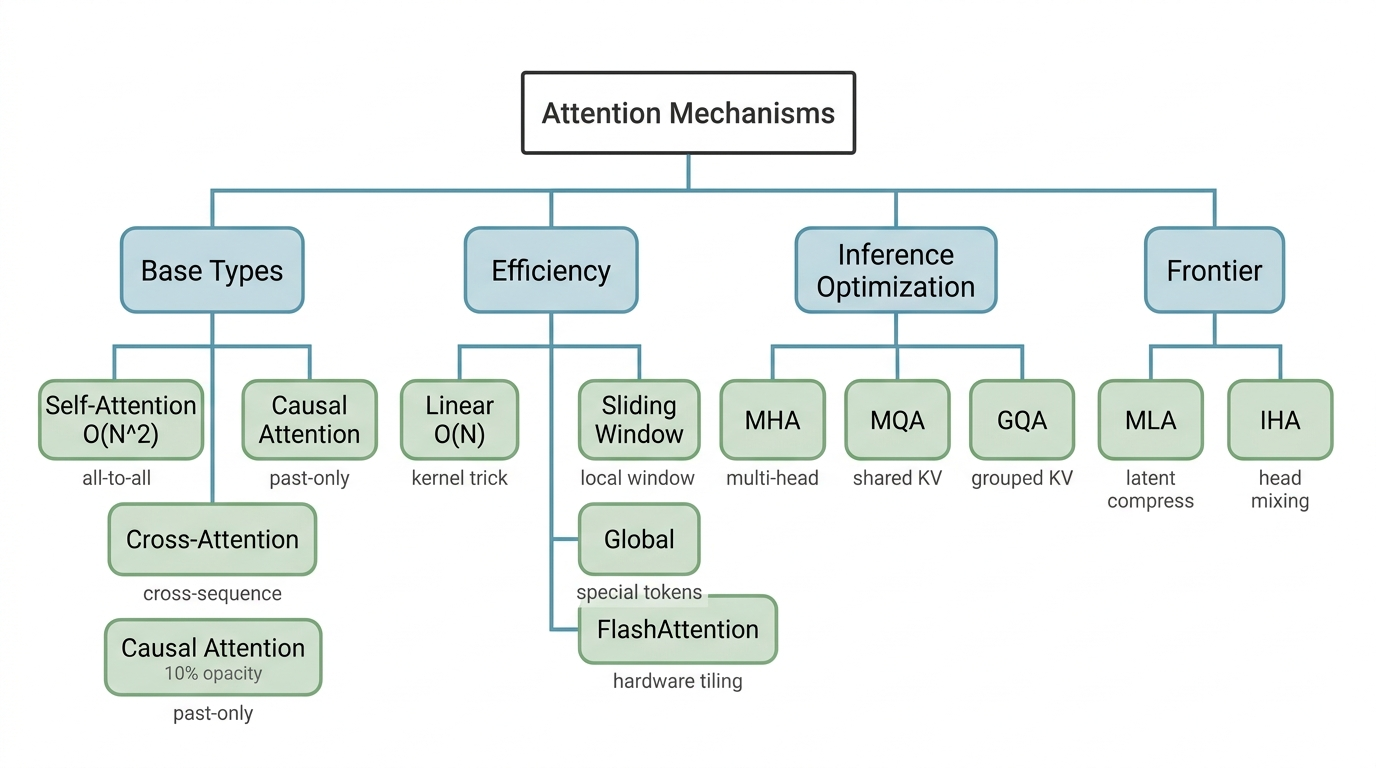 Figure 1. A taxonomy of 13 attention mechanisms grouped by design goal.
Figure 1. A taxonomy of 13 attention mechanisms grouped by design goal.
The core logic: Q, K, V
Every Attention mechanism shares the same foundation. Each token produces a Query ("What am I looking for?"), a Key ("What can I offer?"), and a Value ("Here's my actual content"). The model compares each Q against all Ks, computes similarity scores, then uses those scores to create a weighted combination of Vs.
Think of it like searching a library. Your Q is the question in your head. Each book's K is the blurb on its cover. Its V is the content inside. You wouldn't haul the entire library home. You'd pick the few books most relevant to your question and read those. Attention works the same way.
The differences come down to who compares with whom, over what range, and with what hardware tricks.
Three foundational types
Self-Attention lets every token attend to every other token in a sequence. It captures long-range dependencies but costs O(N squared) in compute, so it gets expensive fast. Cross-Attention lets tokens in one sequence attend to tokens in another, useful for translation and image-text alignment. Causal Attention restricts each token to only see the past and itself, never the future. This is the default for every generative language model.
Each serves a distinct role. When you chat with an AI, Causal Attention drives word-by-word generation. When you upload an image and ask for a description, Cross-Attention aligns visual features to text.
The efficiency battle
When sequences hit 100K or even 1M tokens, O(N squared) breaks down. Linear Attention uses kernel functions to restructure the computation, dropping complexity to O(N). Sliding Window restricts each token to attending only within a fixed neighborhood. Global Attention designates a handful of special tokens that see everything while the rest stay local. Longformer combines the latter two and works well in practice.
FlashAttention takes a completely different approach. Instead of changing the math, it changes how hardware is used. It tiles the Attention matrix into small blocks, computes them in the GPU's fast SRAM, and avoids expensive HBM reads. The result: 2-4x faster inference, lower memory usage, and zero quality loss (Dao et al., 2022).
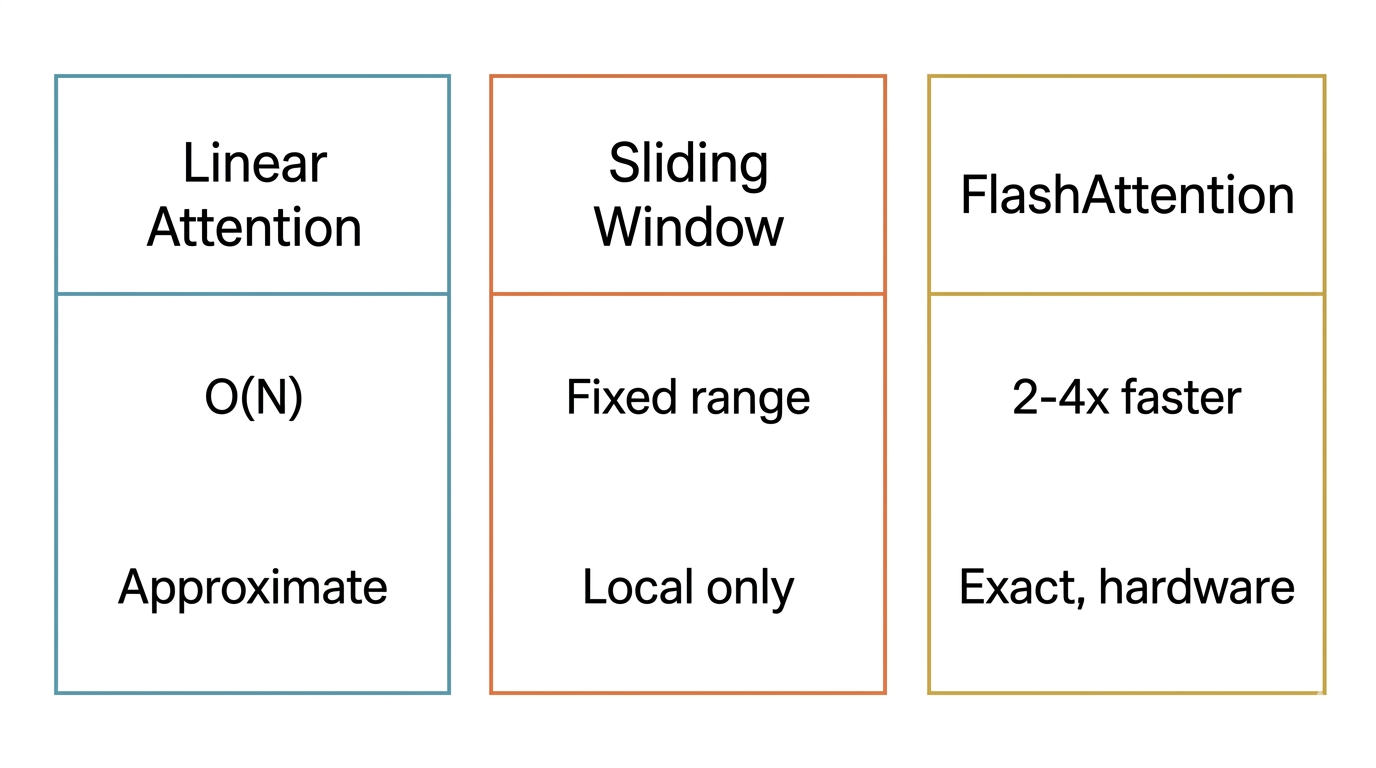 Figure 2. Comparing computational strategies: Linear vs. Sliding Window vs. FlashAttention.
Figure 2. Comparing computational strategies: Linear vs. Sliding Window vs. FlashAttention.
The inference trio: MHA, MQA, GQA
Multi-Head Attention (MHA) is the original Transformer design. It splits Attention into multiple independent "heads," each learning different patterns before merging. The catch: at inference time, every head needs its own KV cache, which eats memory fast.
Multi-Query Attention (MQA) has all Query heads share a single set of Key-Value pairs. KV cache shrinks dramatically and inference speeds up. The cost: quality can dip.
Grouped-Query Attention (GQA) splits the difference. Groups of Query heads share one KV set, keeping most of MQA's speed while recovering nearly all of MHA's quality. Llama 2, Gemini, and most production models use GQA. It's currently the most widely deployed inference optimization (Ainslie et al., 2023).
The frontier: MLA and IHA
DeepSeek-V2 introduced Multi-Head Latent Attention (MLA), which compresses the KV cache into low-dimensional latent vectors for further memory savings. Interleaved Head Attention (IHA) goes further: it mixes heads to form "pseudo-heads," scaling the number of effective attention patterns roughly quadratically with the head count. This makes it particularly strong at multi-step reasoning.
Both are still young. In my testing, MLA delivers noticeable speed gains on long-context tasks with DeepSeek-V2. IHA has fewer large-scale deployment examples so far. Whether they pan out depends on the specific task and model scale.
Why this matters to you
Every time you talk to an AI, Attention mechanisms are running behind the scenes. You can have long conversations on your phone because GQA keeps memory usage manageable. Cloud inference costs can be cut in half because FlashAttention exists. Million-token context windows? MLA is holding the line.
You don't need to memorize any formulas. But next time you drop a 10,000-word document into an AI summarizer and get an answer in two seconds, you'll have a better sense of what made that possible.
FAQ
Q: Why not just pick the "best" Attention mechanism and use it everywhere?
Different mechanisms optimize for different points on the speed-memory-quality spectrum. Self-Attention has the highest fidelity but O(N squared) makes it impractical at scale. FlashAttention accelerates through hardware tricks without changing the underlying math. GQA trades a small quality hit for large inference speedups. In practice, production models combine multiple mechanisms. There is no universal solution.
Q: What does any of this have to do with my experience using ChatGPT or Claude?
Every keystroke triggers an Attention computation that decides which parts of the prior conversation to focus on. Better mechanisms mean longer memory, faster responses, and more accurate answers. GQA and MLA are the unsung technologies behind fast, long-context conversations.
Q: Do these mechanisms have limitations?
Yes. Linear Attention sacrifices precise global attention for speed, which can hurt performance on tasks requiring fine-grained matching, like document-level QA. FlashAttention depends on specific GPU architectures (NVIDIA Ampere or newer), so older hardware misses out. GQA shows more noticeable quality drops on very small models. Choosing a mechanism is always an engineering trade-off. There is no single "best" option.
References
- Vert, A. (2026). 13+ Attention Mechanisms You Should Know. The Turing Post.
- Vaswani, A. et al. (2017). Attention Is All You Need. NeurIPS.
- Ainslie, J. et al. (2023). GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. arXiv preprint.
- Dao, T. et al. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention. NeurIPS.
Frequently Asked Questions
Found this useful?
Follow for new AI × biomedical research notes:
Or buy me a coffee to keep new content coming.
☕ Buy Me a Coffee