
你正在讀這行字的同時,某台伺服器上的 Transformer 模型正在做一個選擇:前面那 10 萬個 token,哪些值得再看一眼?這個選擇的機制叫 Attention。它不只一種,從 2017 年到 2026 年,至少長出了 13 種主要變體,各自在速度、記憶體、品質三角之間押下不同賭注。
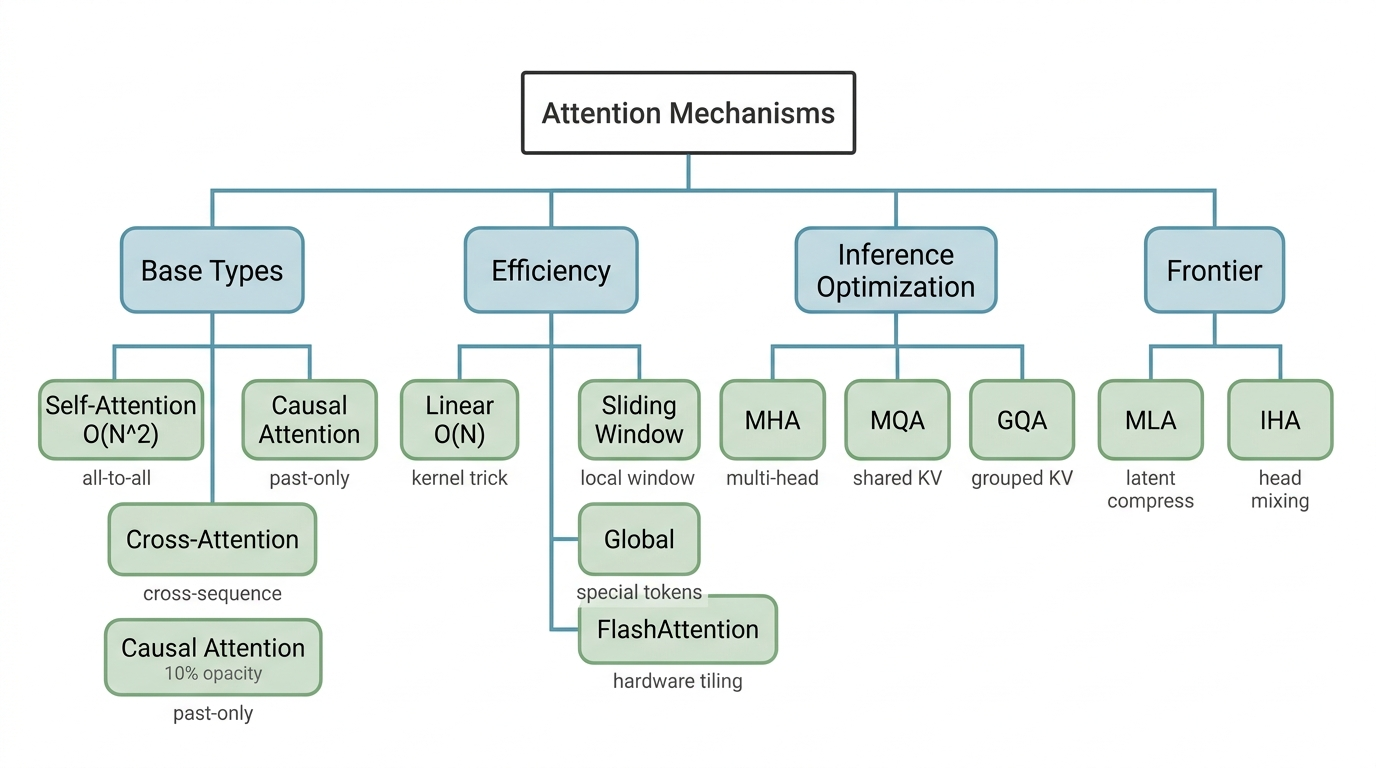 Figure 1. A taxonomy of 13 attention mechanisms grouped by design goal.
Figure 1. A taxonomy of 13 attention mechanisms grouped by design goal.
注意力的基本原理:Q、K、V
所有 Attention 共用同一套底層邏輯。每個 token 發出一個 Query(「我在找什麼?」)、一個 Key(「我能提供什麼?」)、一個 Value(「我的實際內容」)。模型拿 Q 去跟所有 K 比對,算出相似度分數,再用分數加權 V,產生最終輸出。
想像你在圖書館找書。Q 是你腦中的問題,K 是每本書封面的摘要,V 是書的內容。你不會把整間圖書館搬回家,只會挑跟問題最相關的幾本翻。Attention 做的事一模一樣。
差別在哪?誰跟誰比、比多大範圍、用什麼硬體技巧加速。
三大基礎類型
Self-Attention 讓序列中每個 token 都能關注其他所有 token,捕捉長距離依賴,但計算量是 O(N²),序列越長越貴。
另外兩種各管一塊。Cross-Attention 讓一個序列的 token 關注另一個序列,翻譯和圖文配對都靠它。Causal Attention 則限制每個 token 只能看過去和自身,不准偷看未來,所有生成式語言模型都建立在這條規則上。
你跟 AI 聊天時,Causal 負責一個字一個字往下生成。你丟一張圖請 AI 描述,Cross 負責把圖片特徵對齊到文字。
速度與效率的戰爭
序列長度飆到 10 萬甚至 100 萬 token 時,O(N²) 撐不住。怎麼辦?一條路是換公式:Linear Attention 用核函數重構計算,把複雜度壓到 O(N)。另一條路是縮範圍:Sliding Window(局部注意力) 只看固定窗口內的鄰居,Global Attention 則挑少數特殊 token 負責全局視野。Longformer 把後兩者組合在一起,效果不錯。
FlashAttention 走完全不同的路。它不改數學公式,改硬體利用方式:把 Attention 矩陣切成小塊(tiling),在 GPU 的快速 SRAM 中計算,避免昂貴的 HBM 存取。結果?速度快 2-4 倍,記憶體省,品質完全不變(Dao et al., 2022)。
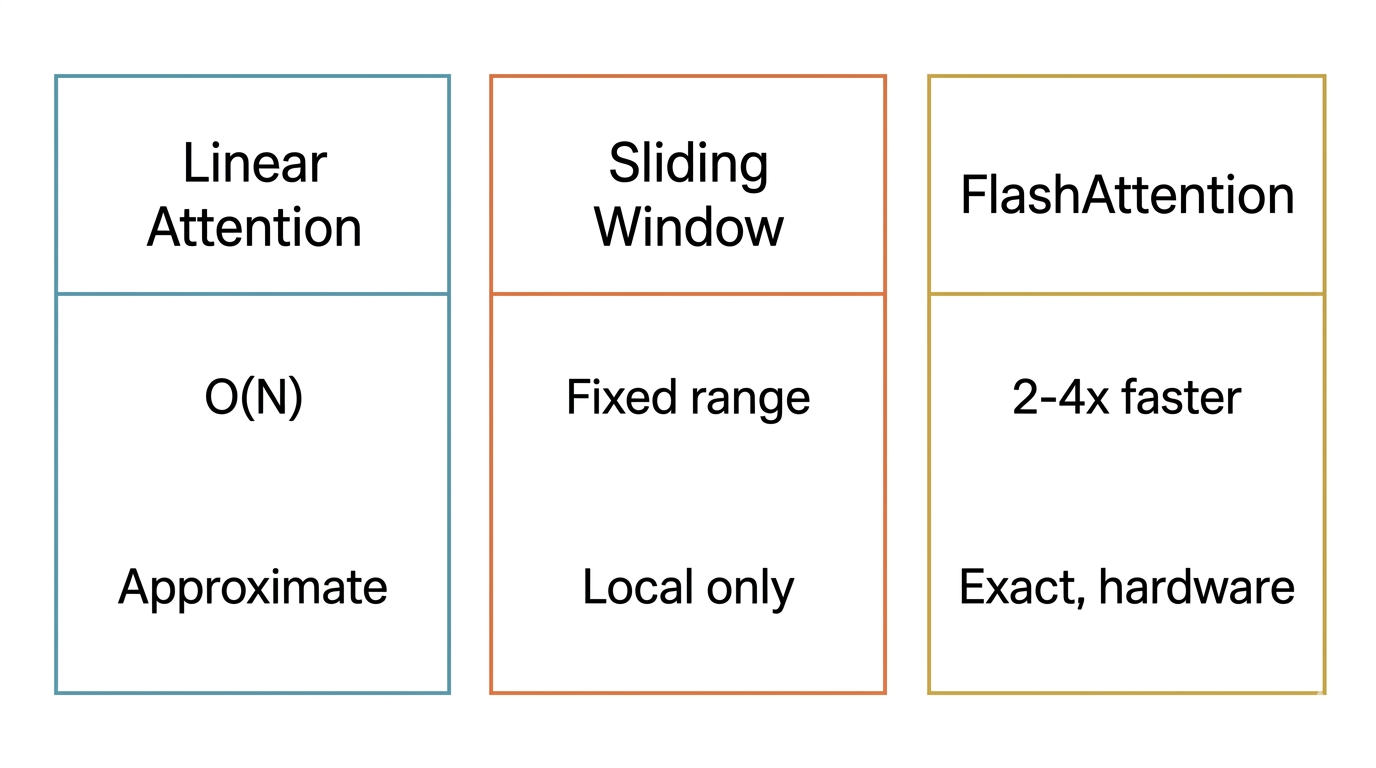 Figure 2. Comparing computational strategies: Linear vs. Sliding Window vs. FlashAttention.
Figure 2. Comparing computational strategies: Linear vs. Sliding Window vs. FlashAttention.
推論時代的三兄弟:MHA → MQA → GQA
Multi-Head Attention(MHA) 是原版 Transformer 的標配,把 Attention 拆成多個獨立的「頭」,各自學不同模式再合併。問題是推論時每個頭都需要自己的 KV cache,記憶體吃很兇。
Multi-Query Attention(MQA) 讓所有 Query 頭共用一組 Key-Value,KV cache 瞬間縮小,推論飛快。代價是品質有時會掉。
Grouped-Query Attention(GQA) 折中處理:每幾個 Query 頭共用一組 KV,既保住 MQA 的速度優勢,又逼近 MHA 的品質。Llama 2、Gemini 等主流模型都採用 GQA。目前,GQA 是部署量最大的推論優化方案(Ainslie et al., 2023)。
前沿:MLA 與 IHA
DeepSeek-V2 推出了 Multi-Head Latent Attention(MLA),把 KV cache 壓縮成低維潛在向量,進一步降低記憶體開銷。Interleaved Head Attention(IHA) 更進一步,讓不同的頭互相混合形成「偽頭」,注意力模式數量隨頭數近似平方成長,擅長多步推理。
這兩個機制都還很年輕。我在測試 DeepSeek-V2 處理長上下文時,確實感受到 MLA 帶來的速度提升,但 IHA 的大規模部署案例還不多。效果好不好,要看具體任務和模型規模。
為什麼這對你有影響
每次你和 AI 對話,Attention 機制都在幕後運作。手機上跟 AI 聊超長對話不會當機,因為 GQA 把記憶體壓下來了。雲端推論成本砍半?FlashAttention 的功勞。至於那個號稱百萬 token 的上下文窗口,背後是 MLA 在撐場。
你不需要記公式。但下次你丟一篇萬字文給 AI 摘要,2 秒就回來的時候,知道背後站著的是哪些機制,會讓你對「AI 為什麼越來越快」這個問題有更踏實的理解。
常見問題
Q:為什麼不直接用最好的一種 Attention 就好?
不同機制在速度、記憶體、精度之間各有取捨。Self-Attention 品質最高,但 O(N²) 在長序列上撐不住。FlashAttention 靠硬體技巧把同一套數學跑快 2-4 倍,不過只有新 GPU 吃得到。至於 GQA,它犧牲一點品質換來大幅推論加速,目前部署量最大。實務上多種機制會混用,沒有萬用解。
Q:這些跟我使用 ChatGPT 或 Claude 有什麼關係?
你每次打字,模型都在用某種 Attention 機制決定該關注前文的哪些部分。機制越好,模型越能記住長對話、回答越準確、回應越快。GQA 和 MLA 是讓你體驗到快速長文對話的幕後功臣。
Q:這些 Attention 機制有什麼侷限嗎?
有。Linear Attention 犧牲了精確的全局注意力換取速度,在需要精細比對的任務(如文件級問答)上可能不如 Self-Attention。FlashAttention 依賴特定 GPU 架構(NVIDIA Ampere 以上),舊硬體吃不到紅利。GQA 在極小模型上品質下降較明顯。選擇哪種機制,永遠是工程權衡,不存在「最好的那一種」。
References
- Vert, A. (2026). 13+ Attention Mechanisms You Should Know. The Turing Post.
- Vaswani, A. et al. (2017). Attention Is All You Need. NeurIPS.
- Ainslie, J. et al. (2023). GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. arXiv preprint.
- Dao, T. et al. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention. NeurIPS.