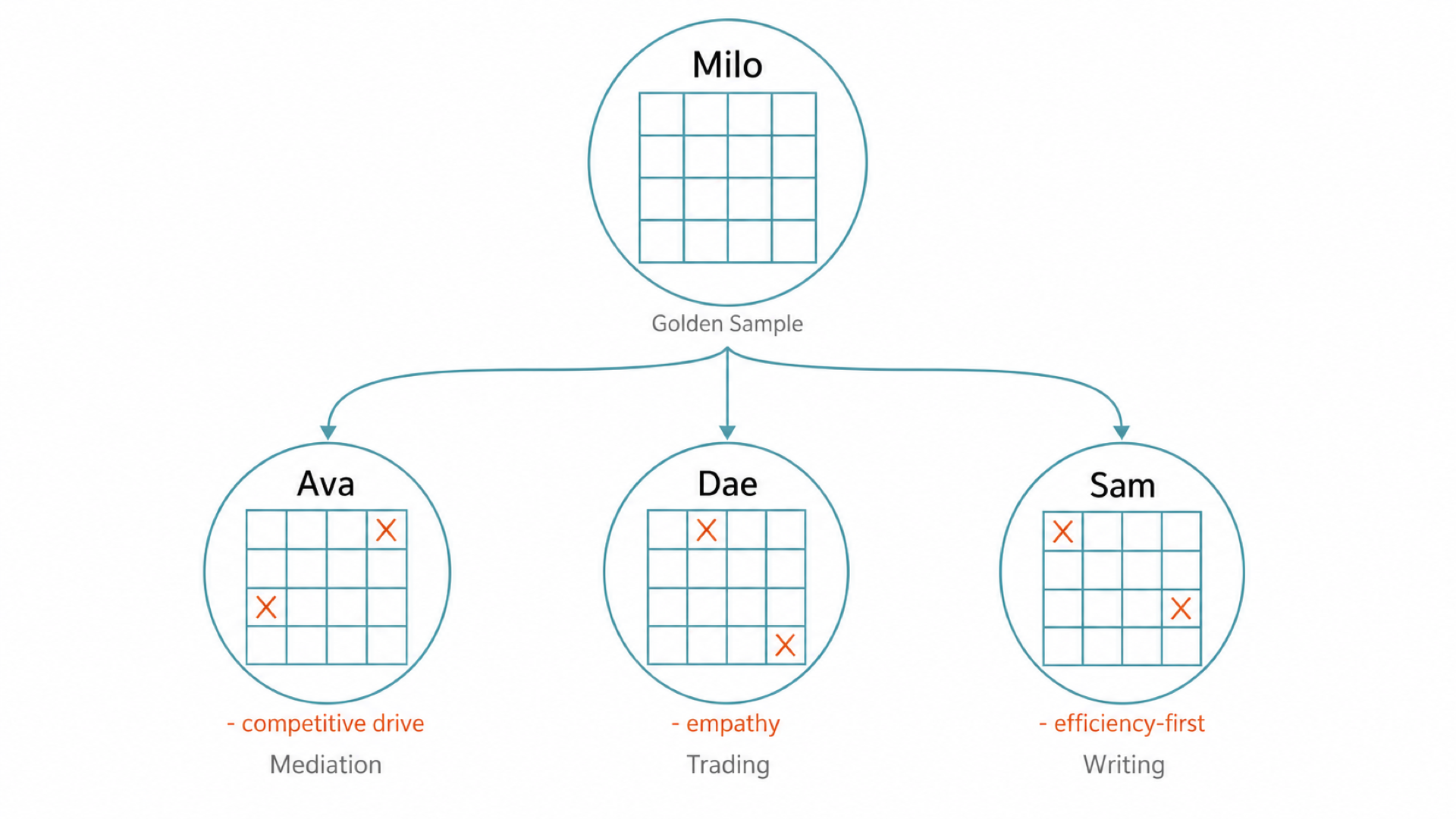
AI 意識即檔案系統:用目錄結構打造 AI 人格
> 導讀:如果 AI「意識」是一堆資料夾——核心信念一層、潛意識藏在隱藏檔裡——你會怎麼設計它?開發者 Amir 真的這樣做了,交出 86.9% 勝率的交易 Agent。Amir 不去定義意識「是什麼」,而是設計它「長什麼樣子」:- kernel/:身份核心,價值觀與底線,不可逾越
生醫研發日誌與技術報告——記錄 AI 整合、流程自動化與濕實驗設計的實戰經驗,所有咒語按時間排列。
> 導讀:如果 AI「意識」是一堆資料夾——核心信念一層、潛意識藏在隱藏檔裡——你會怎麼設計它?開發者 Amir 真的這樣做了,交出 86.9% 勝率的交易 Agent。Amir 不去定義意識「是什麼」,而是設計它「長什麼樣子」:- kernel/:身份核心,價值觀與底線,不可逾越

> 導讀:遇到完全陌生的領域,有人用一套兩年驗證的方法論,搭配 AI,30 分鐘產出結構化研究報告。祕密不在 AI 多聰慧,在於問問題的框架。打開 Google,搜尋 200 萬條結果,看了十篇比開始之前更困惑。問題是沒有認知骨架——骨架搭起來之前,再多資料都是散落的拼圖碎片。這個方法源自 Saussu
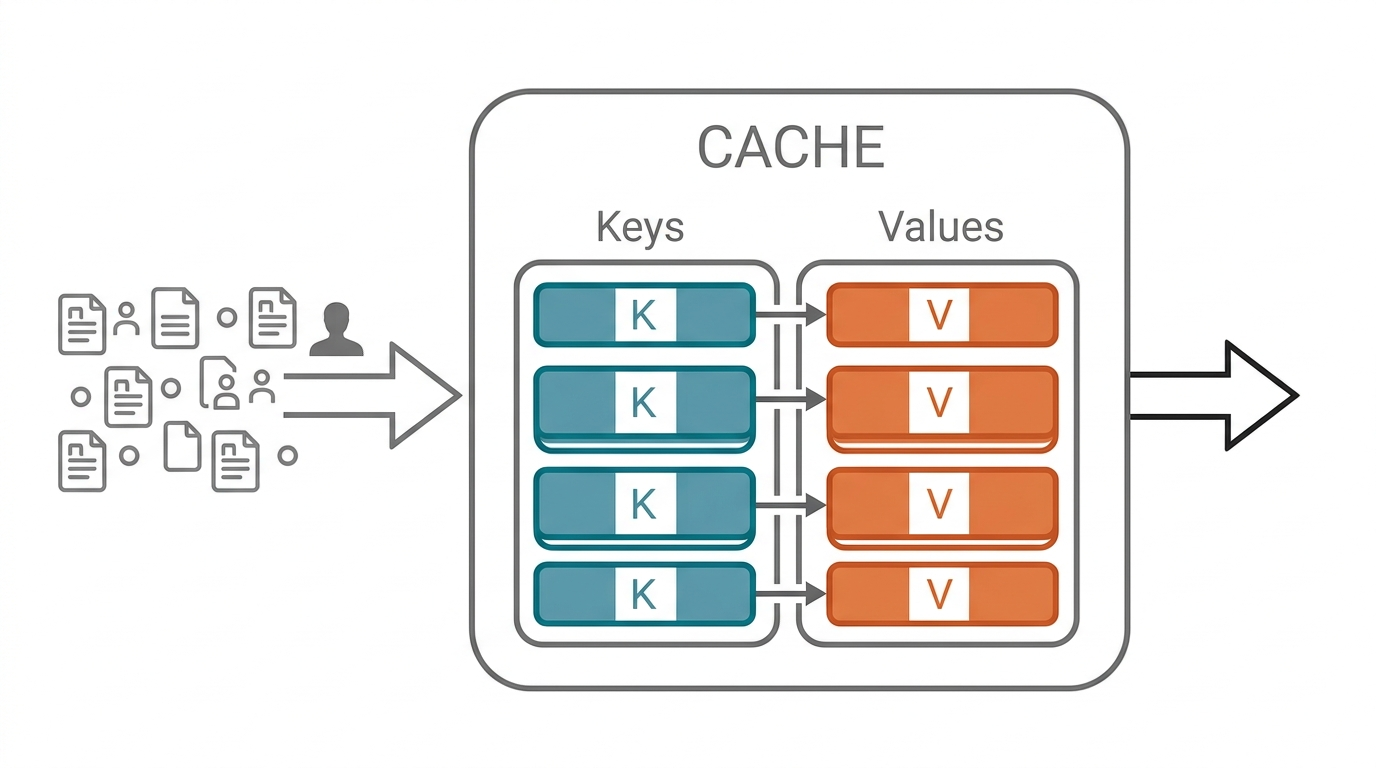
> 導讀:同一個對話問十個問題,為什麼比開十個新對話便宜得多?答案是 KV Cache。掌握它,就能省下 80% 的 Token 成本。十輪對話、每輪輸入 100 個 Token:- 沒有 KV Cache:每輪都重新計算所有舊內容,總計 5,500 Token- 有 KV Cache:
> 導讀:多個 AI 智能體一起工作,不是隨便組合就有效。選對模式系統高效,選錯了再聰明的 Agent 也浪費資源。一個 Agent 生成,另一個驗證品質。過不了就打回重寫。適用:程式碼審查、事實查核、資料驗證。簡單清晰;但驗證者持續不滿意可能陷入迴圈。主 Agent 分解任務,派給多個專屬子 Agent 執行
> 導讀:改進 Harness 設計,同一模型的 TerminalBench 排名從第 30+ 名跳到第 5 名。沒換模型,沒增加參數。LLM 無法看螢幕、執行程式碼、記住昨天的對話。這不是模型的問題——是缺乏「身體」的問題。Harness 就是這個身體。@akshay_pachaar
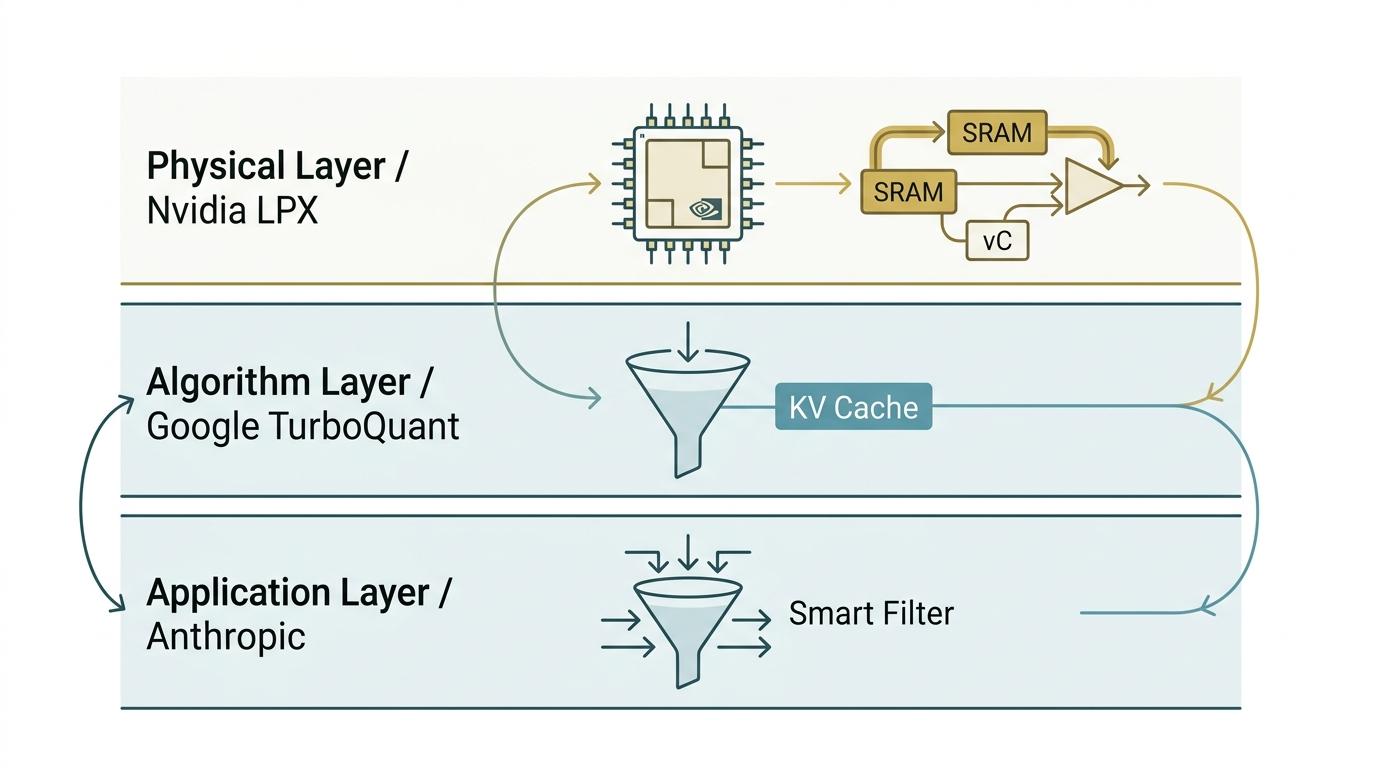
> 導讀:AI 要說話更流暢,需要更大的記憶體?真相更有趣——瓶頸不在容量,而在資料流動速度。Nvidia、Google、Anthropic 各守一個系統層,方案彼此互補,不是競爭。每產生一個詞彙,模型都要從記憶體讀取大量狀態;讀取慢 = 整體被拖累。加更多容量解決不了——高速公路再寬,堵車時一樣動不了。