
TL;DR: Claude Max costs $200/month. One afternoon of researching 47 papers burned through five days of quota. The fix isn't prompt caching. It's making sure your papers never enter Claude in the first place.
The Problem: You're Using Claude as a Full-Text Search Engine
Dump 50,000 words of research papers into a Claude conversation, and every follow-up question re-bills the entire input. Prompt caching helps — it cuts per-token cost to 1/10 — but the cache expires after one hour. Pause to think, switch tabs, start a new session, and you're back to full price.
Research sessions are inherently stop-and-go: ask a question, think for a few minutes, ask another. Cache hit rates are brutal. It's like asking your lawyer to re-read your entire 50-page contract from scratch every time you have a question.
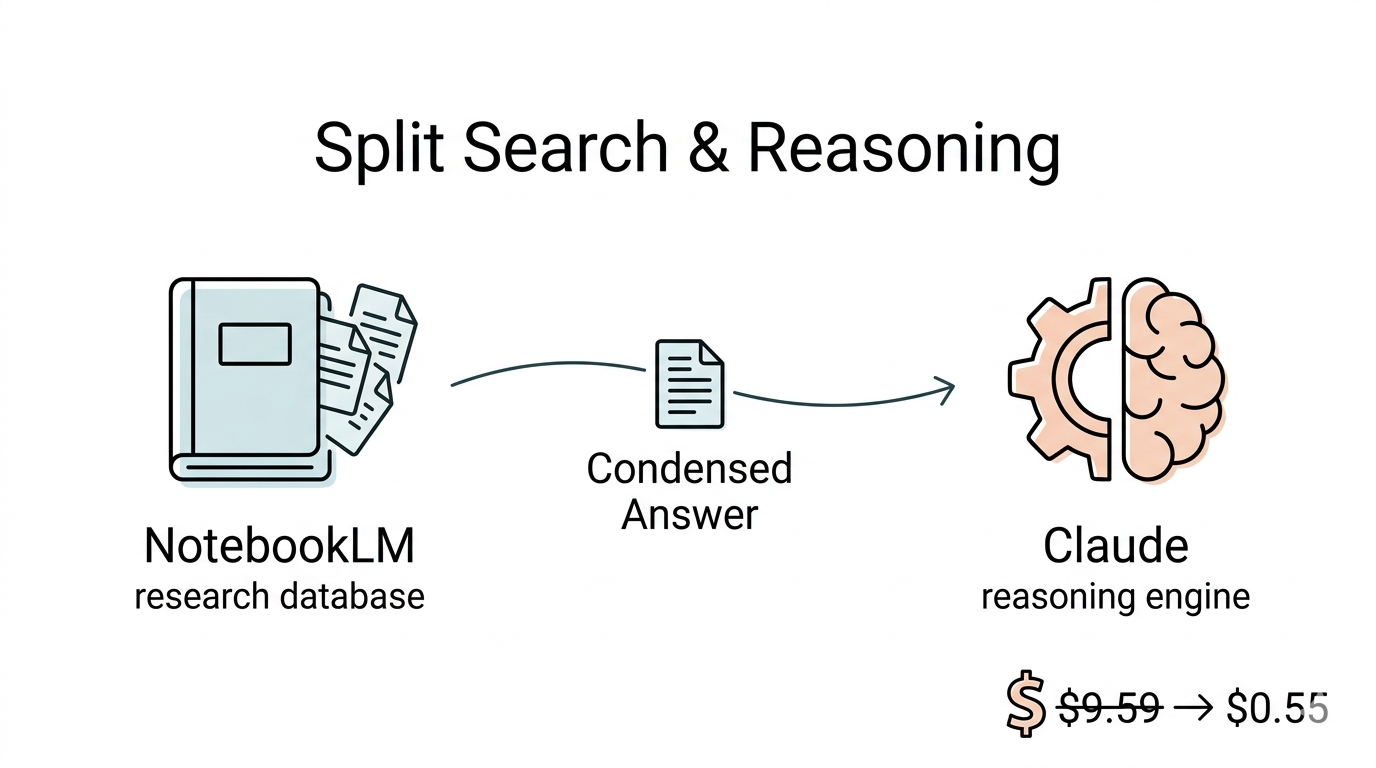
The Fix: NotebookLM as Teacher, Claude as Assistant
NotebookLM stores and retrieves your corpus. Upload all 47 papers, let Google's infrastructure handle vector search — completely free. Every answer is grounded in your sources with inline citations. No extrapolation.
Claude handles reasoning and orchestration: writing code, running scripts, compiling results, chaining tools. When it needs domain knowledge, it asks NotebookLM for a cited answer and keeps working.
You are the principal investigator. You step in only at decision points.
The core principle: raw papers flow through NotebookLM's RAG pipeline (Google's free tier), and Claude only ever sees a few hundred tokens of distilled, cited answers. Cost shifts from "scales linearly with corpus size" to "roughly constant."
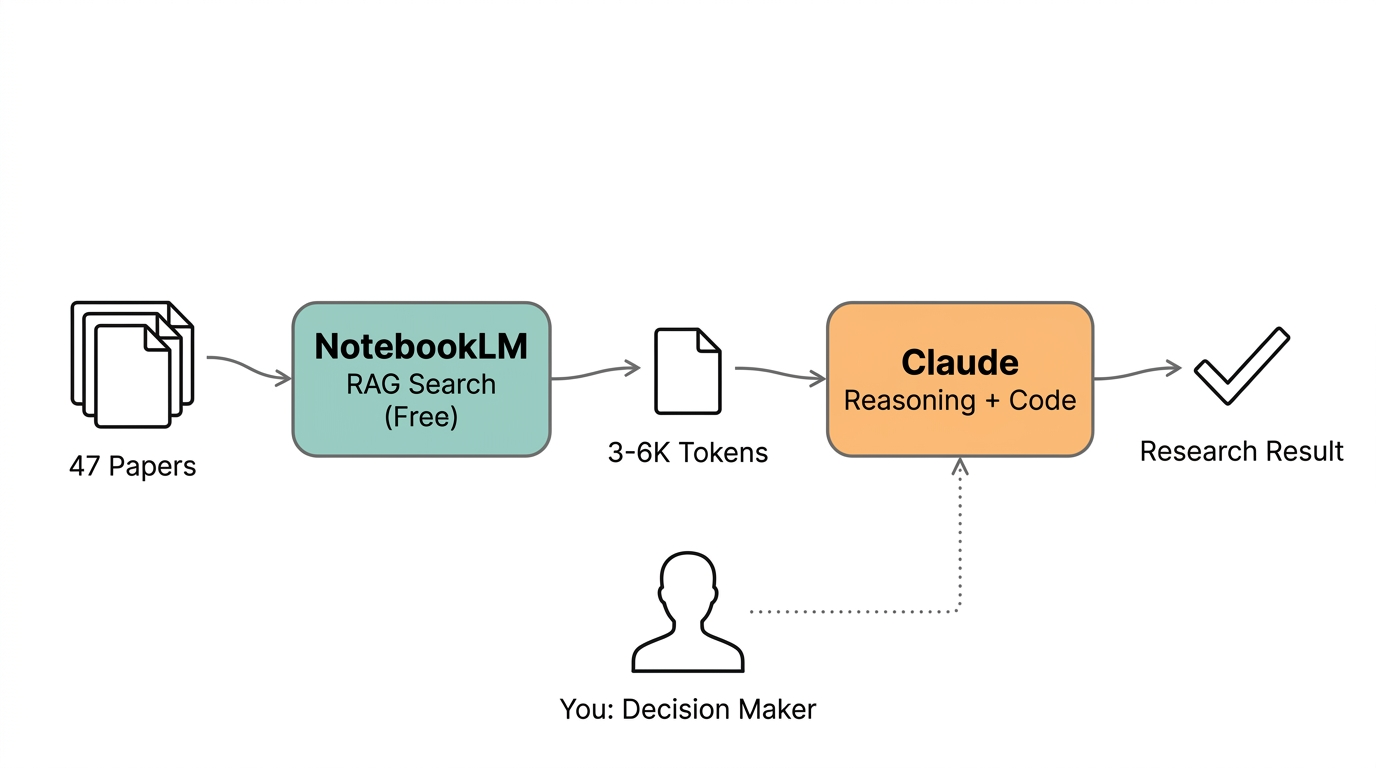
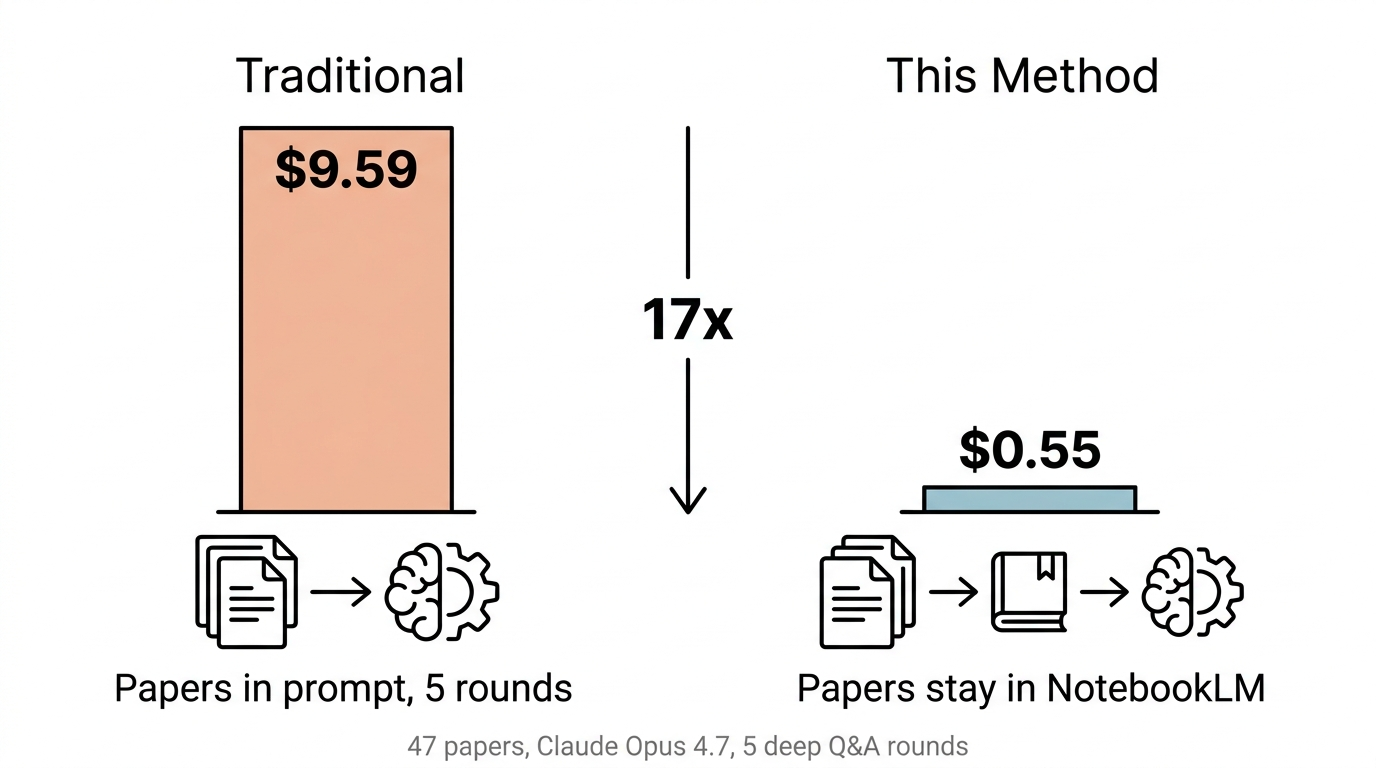
The Numbers
47 computer vision and LiDAR SLAM papers. Claude Opus 4.7. Five rounds of deep Q&A.
This method: five rounds totaling $0.55 in token costs, averaging $0.11 per round. Cache creation hit only 17,379 tokens — because only each round's teacher answer (3–6K tokens) entered the cache. Not a single word from those 47 papers touched Claude.
Traditional approach (papers in prompt): same session, multiple rounds, best-case cache scenario — five rounds cost $9.59. Cross-session with cache misses? $47.50.
The gap: 17x in the best case, 86x in the worst. Double your corpus, and the gap widens linearly.
The Trade-off: 3x Slower
NotebookLM's median query latency is about 45 seconds. Factor in Claude's own response time, and the overall experience runs roughly 3x slower. If you optimize for response speed over monthly bills, this setup isn't for you.
But for research tasks, 45 seconds per teacher answer versus running out of quota on day five? The math speaks for itself.
Three Scenarios Where This Shines
Academics and students: A semester's reading list — dozens of PDFs queried hundreds of times. Load them into NotebookLM. Claude drives the research forward: ask the teacher for concepts and formulas, write code to replicate experiments, run analyses, compile notes.
Prospectus analysis: A single 500-page prospectus runs 150K–250K tokens. Covering 5–8 IPOs a week? Traditional approach burns $50+ on corpus alone. This method: under $2.
Personal knowledge bases: Export your entire Obsidian vault into NotebookLM. Claude handles cross-document thematic analysis and structured summaries.
The common thread: repeated queries, cross-file retrieval, private data boundaries. Hit any one of those, and the setup cost pays for itself within a week.
Why This Matters for You
The real cost of AI tools isn't the subscription — it's the tokens you waste under the wrong architecture. Separating search from reasoning, letting cheap tools search and expensive tools think, is the first principle of AI workflow cost control.
A $20 account doing $200 worth of work isn't magic. It's division of labor.
FAQ
Q: Doesn't NotebookLM hallucinate too? A: NotebookLM constrains every answer to your uploaded sources, with inline citations like [1][2] you can click to verify. It won't fabricate information beyond your documents. Claude making decisions based on cited answers is far more reliable than relying on its own memory.
Q: What if my corpus is tiny — under 5,000 tokens? A: Then skip this setup. For small corpora with one or two queries, just ask Claude directly. This architecture pays off when you query repeatedly, across many files, within a private boundary — think literature reviews, prospectus analysis, or personal knowledge bases.
References
- MinLi (2026). Save 80% Tokens with NotebookLM. X thread.
- Anthropic (2026). Prompt Caching documentation.
Frequently Asked Questions
Found this useful?
Follow for new AI × biomedical research notes:
Or buy me a coffee to keep new content coming.
☕ Buy Me a Coffee