
TL;DR: You connected your AI Agent to Slack, Google Drive, and CRM. It can search everywhere. But ask it the same question from different tools and you get different answers. Ask who owns your biggest account and the answer changes day to day. The problem isn't access. It's that your AI can reach everything yet comprehends nothing.
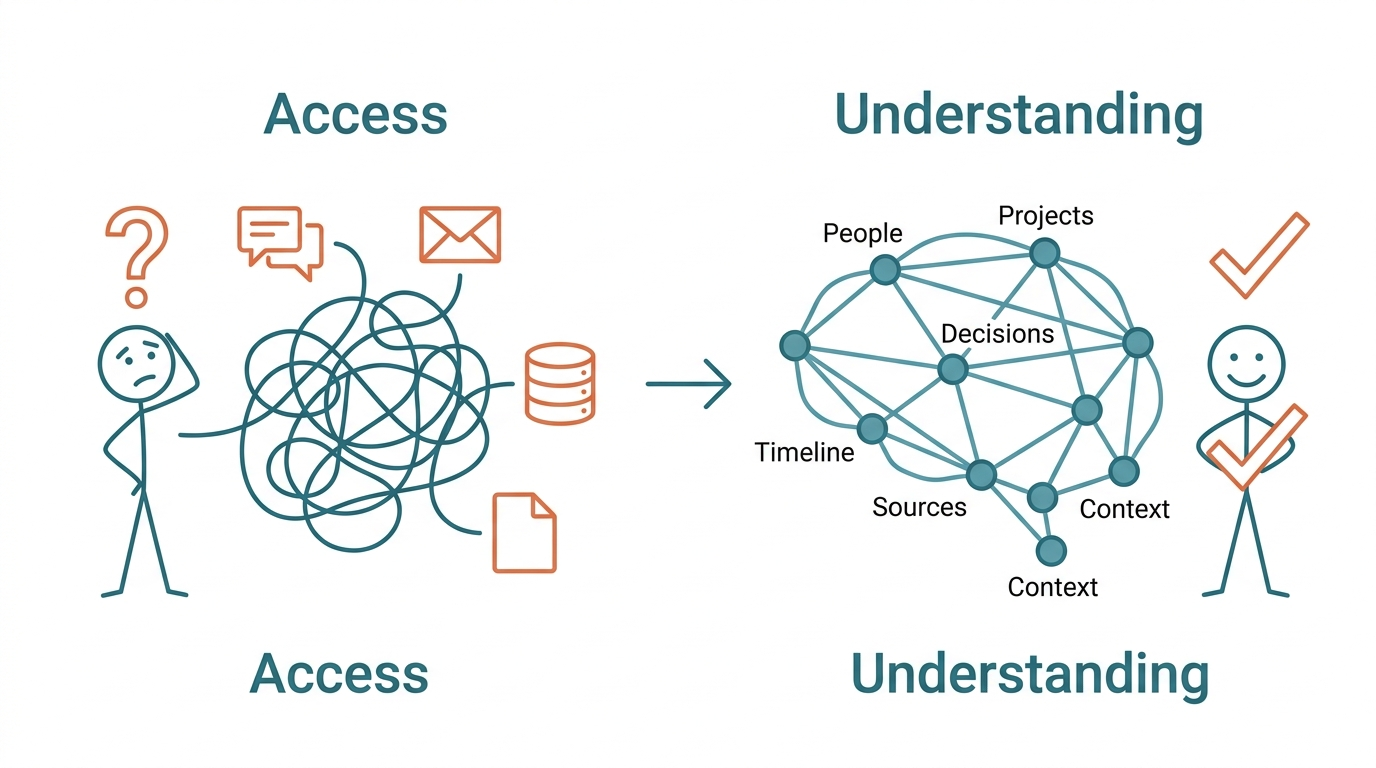
Access ≠ Understanding
Being able to search all your data doesn't mean being able to make the right call. The value of information isn't in its volume — it's in what you can synthesize from it.
Picture a new hire on their first day. You hand them passwords to every system. They can search Slack, read Google Drive, query the CRM. But they don't know which Slack channel is where real decisions happen and which is theater. They don't know the CRM says the deal closed in March, but the handshake actually happened over dinner in January. They have no idea what changed last week or why priorities shifted this week.
A great chief of staff knows everything after six months. Not because they got more access — because they synthesized hundreds of signals into a mental model more accurate than any single source.
No AI Agent does this today. Does yours?
RAG's Fundamental Limits
RAG solved "finding." It hasn't solved "understanding." Every query starts from zero — no memory, no accumulated judgment.
The industry framed the problem as retrieval: how do you get the right information to the agent at the right time? So we built RAG pipelines, vector databases, semantic search, MCP servers. All retrieval infrastructure.
But retrieval is a treasure hunt. Every time the agent needs context, it searches from scratch. No prior understanding, no accumulated knowledge, no awareness of what changed since last time.
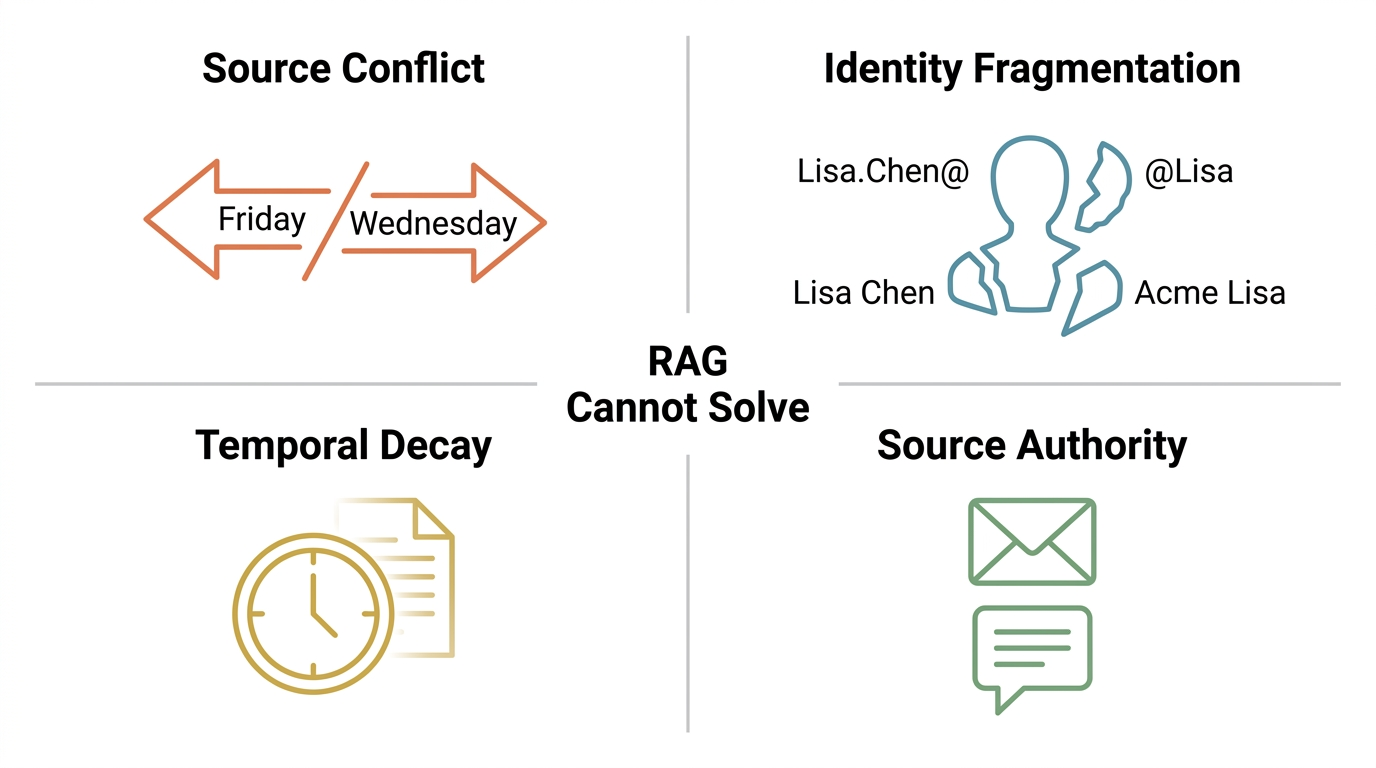
Four problems RAG can't solve:
- Source Conflict: Slack says the deadline is Friday. Linear says next Wednesday. The PM said end of month in last week's meeting. RAG returns whichever it finds first.
- Identity Fragmentation: The same person is Lisa.Chen@acme.com in email, @Lisa in Slack, "Lisa Chen" in CRM, and "Lisa from Acme" in meeting notes. RAG treats them as five different people.
- Temporal Decay: A strategy document from January is stale, but RAG presents it with the same confidence as yesterday's update.
- Source Authority: When the CEO's email contradicts a random Slack message, the email wins. RAG has no concept of this.
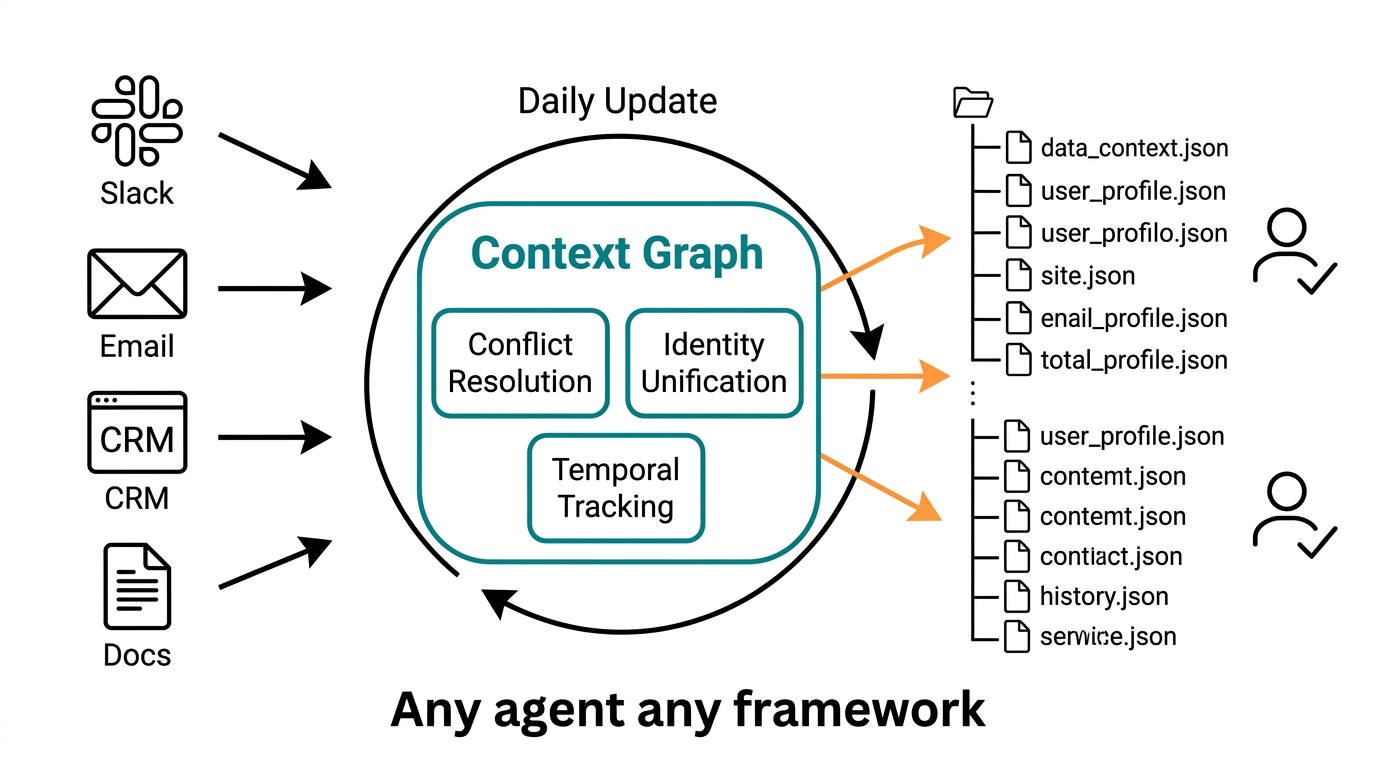
Context Graph: A Continuously Updating Corporate Brain
The answer should exist before the question is asked. That's the core claim of the Context Graph — instead of searching at query time, it pre-builds a continuously updated model of enterprise understanding.
The alternative is synthesized understanding. Build a model that continuously resolves conflicts, tracks sources, unifies identities, and marks temporal relevance. The agent doesn't search — it reads, because understanding has already been pre-computed.
The Context Graph's delivery interface is the file system. Every agent already knows how to read files. Claude Code reads project directories. Cursor reads codebases. The Context Graph outputs structured files that any vendor, any framework can consume directly — no custom integration needed.
But files are just the output. The real product is the synthesis that happens before files are written: resolving conflicts, ranking sources, tracking freshness, building identity maps across fragmented mentions. This interpretive work used to require someone who'd been at the company for six months.
The Compound Effect
The gap between day one and day thirty isn't incremental — it's qualitative. The Context Graph improves every day. On day one, it knows almost nothing. By day thirty, it has absorbed thousands of messages, hundreds of documents, dozens of meetings. It has resolved conflicts, built identity maps, tracked what changed and what didn't.
You can't throw money at this to skip the process. Every day you don't run it is a day you fall behind. This is the real moat — not the technology (which can be copied), but your company's unique accumulated understanding.
That said, the system has its boundaries. The Context Graph needs time to warm up; its judgment during cold start is limited. Its quality depends entirely on source quality — if your Slack is full of noise and your CRM hasn't been updated in six months, the "understanding" it synthesizes will be off. Continuous syncing and conflict resolution require compute resources; this isn't a free lunch. But these very barriers to entry make the first-mover advantage harder to catch.
Why This Matters to You
In 2025, the industry solved "connection" — MCP servers, API integrations, tool access. The 2026 battleground is "understanding" — cross-source synthesis, conflict resolution, temporal tracking. Whoever gets AI to truly understand their organization first will be very hard to catch in the agent era.
How many AI agents does your company run today? How many of them actually "get" your organization?
Access is the entry ticket. Understanding is the differentiator.
References
- Conor (2026). Your company needs a brain, not more connectors. Hyperspell blog.
- Karpathy, A. (2026). AI Knowledge Base architecture. GitHub.
Frequently Asked Questions
Found this useful?
Follow for new AI × biomedical research notes:
Or buy me a coffee to keep new content coming.
☕ Buy Me a Coffee