The AI Arms Race Winner Won't Be the One With the Best Model — How Harness Became the Real Moat
🧪 AI ToolsThe AI Arms Race Winner Won't Be the One With the Best Model — How Harness Became the Real Moat
TL;DR: For three years, the AI industry competed on parameter counts and benchmarks. Then 2026 happened: LangChain jumped 25 spots on TerminalBench without changing its model, three tech giants poured billions into deployment engineers, and a group of crypto-native founders built the fastest-growing AI repo in history. All three events point to the same conclusion — the decisive edge in AI has moved from "better models" to "better everything around the model."
A Ranking Reversal
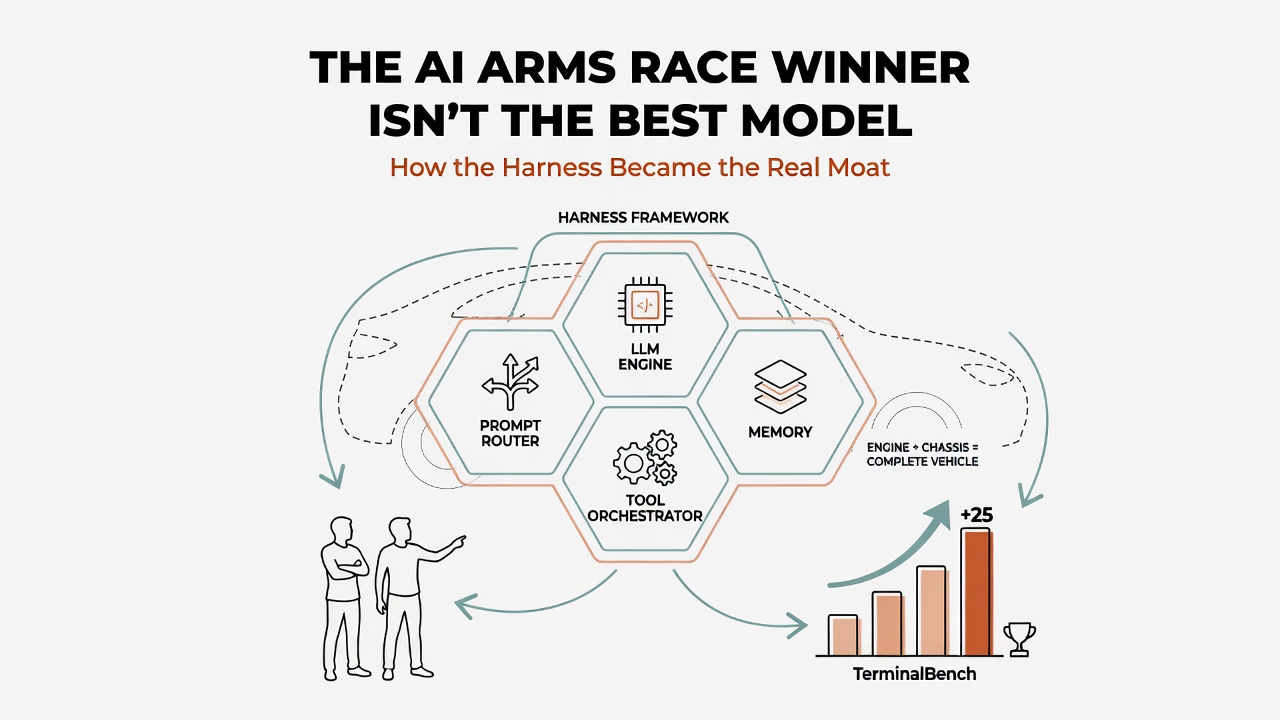
LangChain was ranked outside the top 30 on TerminalBench 2.0, a benchmark measuring how well AI agents handle command-line tasks. They made one change: they redesigned the harness wrapping their large language model. Same model, same parameters. The result? They shot up to 5th place.
Around the same time, Andrej Karpathy publicly complained about three bad habits of Claude when coding: making silent wrong assumptions, over-engineering solutions, and touching code it shouldn't. Forrest Chang distilled those complaints into four rules, packaged them in a file called CLAUDE.md, and posted it on GitHub. It earned 5,828 stars on day one, 60,000 bookmarks in two weeks, and has since accumulated over 120,000 stars — the fastest-growing single-file repo of 2026. Subsequent testing across 30 codebases over six weeks showed that error rates dropped from 41% to 11%. With eight additional rules, the rate fell to 3%.
Both stories say the same thing: the model didn't change, but what surrounded it did — and performance shifted dramatically.
That "surrounding stuff" now has a formal name.
What Is a Harness? And Why It's an Operating System
Vivek Trivedy of LangChain offered a clean definition: "If you're not the model, you're the Harness."
A Harness is the complete software architecture wrapping an LLM — orchestration loops, tool calling, memory management, context control, state persistence, error handling, and safety guardrails. Anthropic's official documentation describes its SDK as "the Agent Harness that powers Claude Code." OpenAI's Codex team uses the same framing.
Many people confuse "AI Agent" with "Harness." The distinction: an Agent is the behavior users perceive (a goal-directed entity that uses tools and self-corrects), while a Harness is the machinery that produces that behavior. Saying "I built an Agent" really means "I built a Harness and plugged a model into it."
Beren Millidge drew a precise analogy in 2023: a bare LLM is a CPU with no RAM, no hard drive, and no I/O devices. The context window serves as RAM (fast but limited), external databases act as storage (large but slow), and tool integrations are device drivers. The Harness is the operating system.
Millidge's conclusion: "We've reinvented the von Neumann architecture."
Twelve Gears: The Internals of a Production Harness
A production-grade Harness contains at least twelve interrelated components, organized into five critical areas:
The Orchestration Loop sits at the heart — a think-act-observe cycle that assembles prompts, calls the model, parses outputs, executes tools, feeds results back, and repeats. Anthropic describes its own runtime as a "dumb loop" where all intelligence resides in the model; the Harness merely manages turn-taking.
Tools and Memory give the agent its hands and brain. Tools enable file operations, code execution, search, and web access. Memory operates across time horizons: short-term within a session, long-term across sessions. Claude Code implements a three-tier memory architecture — lightweight indexes always loaded, topic files called on demand, and raw records accessible only via search.
Context Management is where things most often go wrong. Stanford's "Lost in the Middle" research showed model performance drops over 30% when critical information sits in the middle of the context window. Production solutions include compression, observation masking, just-in-time retrieval, and sub-agent delegation.
Verification Loops separate toys from production systems. A ten-step workflow at 99% per-step accuracy yields only 90.4% end-to-end. Boris Cherny, creator of Claude Code, reports that enabling self-verification improves output quality 2 to 3x.
Guardrails and Safety enforce what the model is allowed to do, architecturally separated from what the model wants to do. This single design principle matters more than any safety paper.
Industry: Deployment Is Now Worth More Than Training
OpenAI launched a "deployment company" in May 2026. TPG, Advent, and other PE firms invested $4 billion at a $14 billion valuation. OpenAI simultaneously acquired UK-based Tomoro, absorbing 150 Forward Deployed Engineers (FDEs) — a hybrid role spanning software engineering, solution architecture, and consulting.
Anthropic followed suit, partnering with BlackRock and Goldman Sachs to form an independent FDE consulting firm with $1.5 billion in initial investment, targeting mid-market enterprises.
Google took its own approach, compressing FDE interviews from four-to-six rounds to two rounds over two days, with senior total compensation exceeding $400,000 in the US.
Three AI giants making the same bet simultaneously: for every dollar spent training a model, another dollar may be needed to make it actually work in production. The FDE role is essentially a human-shaped Harness — translating model capabilities into forms that customer business systems can digest.
From 8 Followers to a $1 Billion Valuation
While industry titans competed for FDEs, a different force was proving the Harness thesis from the outside.
NousResearch's open-source project Hermes Agent accumulated 128,000 GitHub stars in seven weeks — a trajectory that took LangChain the better part of a year. The founding team brought three genes directly from web3: open source as competitive strategy (MIT License from day one), community operations expertise (the kind that turns volunteers into code and compute contributors), and cycle immunity (the resilience to make decisions amid chaos without being spooked by short-term volatility).
Hermes Agent didn't go viral because of model quality alone (it ran GPT-5.5 on the backend). It exploded because it decomposed long-running agent capabilities more granularly — autonomous memory updates, skill routing, session continuity, scheduled tasks, observability. The real differentiator was the control plane outside the model.
What You Can Take Away
A word of caution: the TerminalBench story is compelling, but LangChain showed limited improvement on SWE-bench, which demands deep reasoning. Harness amplifies existing model capabilities; it cannot conjure reasoning depth the model lacks. Harness also requires ongoing maintenance — every model upgrade can invalidate prompt engineering, tool interfaces, and context strategies.
For developers: Before blaming the model, audit your Harness. Is context rotting? Are verification loops in place? Are tool permissions scoped to the minimum needed?
For decision-makers: The $14B deployment company and $1.5B FDE consulting firm signal that "making models work" is rapidly approaching the commercial value of "making models better."
For general users: You don't need to understand all twelve components. Start with the lightest Harness you can — a well-written CLAUDE.md. Four rules dropped error rates from 41% to 11%. That's a performance gain anyone can capture in ten minutes.
Conclusion
The AI industry in 2026 is undergoing a quiet power shift. On the surface, the parameter arms race continues. Underground, the real decisive edge has moved. LangChain rewrote rankings with Harness engineering, three giants bet tens of billions on deployment, and NousResearch defeated competitors with a hundred times their resources using community and architecture design.
Millidge was right: we've reinvented the von Neumann architecture. The LLM is the CPU, the Harness is the operating system. And in the history of computing, the operating system winner has never been the CPU manufacturer.
References
- Akshay Pachaar, "The Anatomy of an Agent Harness" — Harness 12-component breakdown, TerminalBench ranking data, Beren Millidge von Neumann analogy, Vivek Trivedy definition
- @Xudong07452910, "7-week 128K stars: Hermes Agent" — NousResearch founding story, Teknium/Bowen Peng profiles, Paradigm Series A, web3 DNA analysis
- @xxxjzuo, "From OpenClaw to Hermes: Re-examining Agentic AI Architecture" — Personal Agent runtime 7-layer architecture, skill routing, memory governance
- @dotey, "Forward Deployed Engineer: The Hot New Role of the AI Era" — Google/OpenAI/Anthropic FDE arms race, OpenAI deployment company $14B valuation
- @cat88tw, "LLM/Harness/Agent: What's the Difference" — Concept clarification
- @Mnilax, "Karpathy's 4 CLAUDE.md rules" — Error rate from 41% to 11%, 12 rules to 3%, compliance vs. rule count relationship
Found this useful?
Follow for new AI × biomedical research notes:
Or buy me a coffee to keep new content coming.
☕ Buy me a coffee