導讀:所有現代 AI 的核心引擎都是 Transformer,Transformer 的靈魂是「注意力機制」。它靠三個矩陣——Query、Key、Value——讓 AI 學會「哪些字跟哪些字有關」。邏輯跟圖書館找書一模一樣。
圖書館比喻
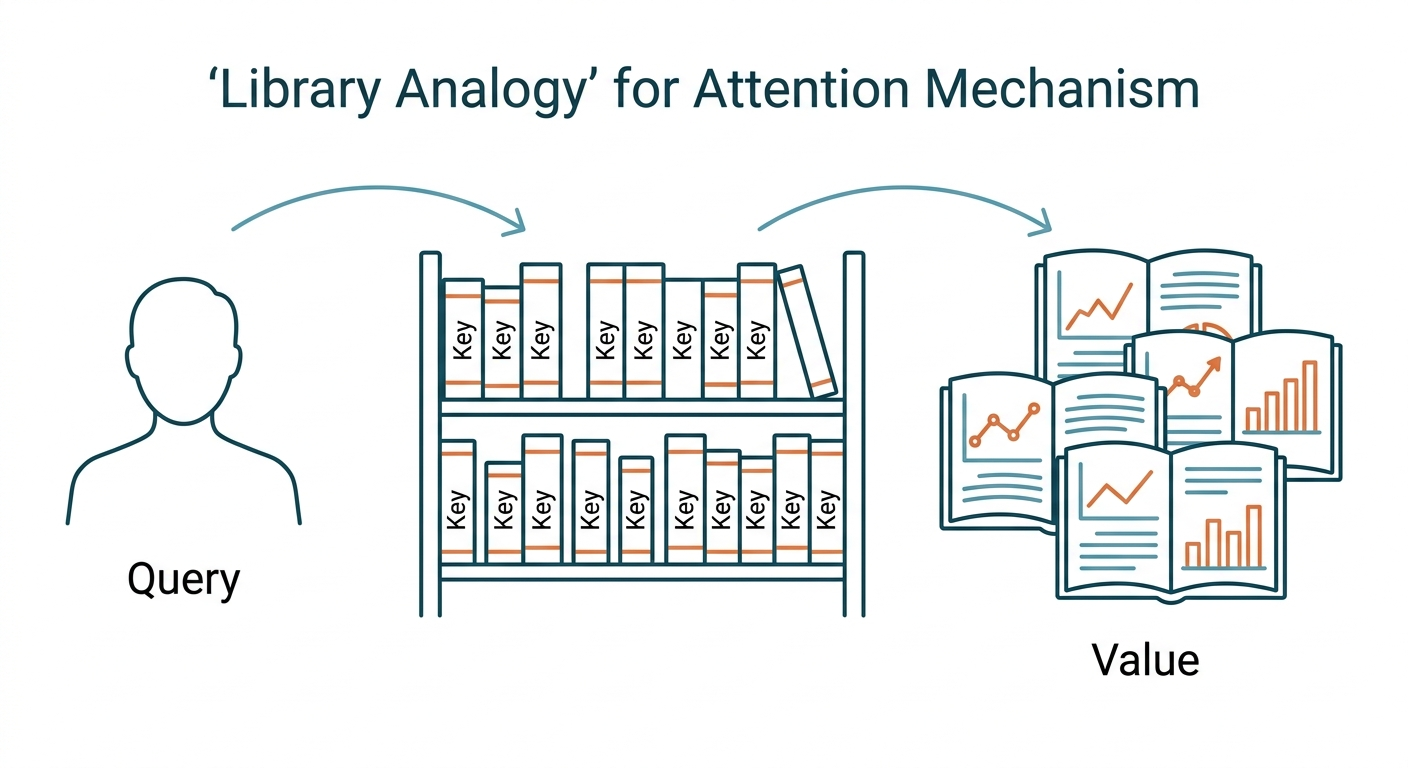
你走進圖書館想找「蛋白質摺疊」的資料。腦中的問題是 Query(查詢);書架上每本書的標題與關鍵字是 Key(索引鍵);書裡的圖表、公式、數據是 Value(值)。
你拿 Query 去比對每本書的 Key,找到最相關的幾本,把它們的 Value 混在一起,得到答案。AI 的注意力機制做的事情完全一樣——只是用向量點積取代文字比對。
一句話走一遍流程
「I love AI」這三個字,每個字同時扮演三個角色:想知道誰跟自己最有關時是 Query;讓別人判斷自己重不重要時是 Key;被選中、需要貢獻資訊時是 Value。
每個字先轉成 embedding 向量,分別乘以三個權重矩陣,產生 Q、K、V——這三個矩陣是模型在訓練中自己學出來的。
注意力分數:誰跟誰有關?
把一個字的 Q 向量和另一個字的 K 向量做點積,數值越大代表越相關。為防止高維度讓點積數值過大(softmax 後一個字搶走所有注意力),除以維度平方根 √d_k,再做 softmax 轉成機率。每個字對其他字的注意力權重加起來剛好是 1。
加權混合
用注意力權重對所有字的 Value 向量做加權平均。結果:每個字的輸出不再只代表自己,而是「根據上下文重新定義的自己」。
「bank」出現在「river bank」旁邊,輸出偏向「河岸」;出現在「bank account」旁邊,同一個字偏向「銀行」。注意力機制讓每個字根據鄰居動態調整意義。
為什麼這個設計這麼成功?
前代主流方法 RNN 從頭讀到尾,讀到句尾時句首資訊已模糊。注意力機制讓每個字直接看到所有其他字,不管距離多遠——像用索引跳頁而非從第一頁翻起。這使 Transformer 能平行運算、處理超長文本,並碾壓前代架構。
2017 年 Google 的 "Attention Is All You Need" 發表時,大概沒人預料到 Q、K、V 三個矩陣不到十年內會重塑整個科技產業。
三個字母,一個公式,改變了人類與機器溝通的方式。
References
- Shekhar, A. (2026). Math behind Attention - Q, K, and V.
- Vaswani, A. et al. (2017). Attention Is All You Need. NeurIPS 2017.
- Jay Alammar (2018). The Illustrated Transformer. jalammar.github.io.
常見問題
Attention 機制只有 Transformer 才用嗎?
不是。Attention 最早源自機器翻譯研究,後來被 Transformer 採用並推廣,現在也出現在圖像識別(Vision Transformer)、蛋白質摺疊預測(AlphaFold)等領域,是通用機制。
Q、K、V 的類比夠準確嗎?真實情況有什麼不同?
類比幫助直覺,但現實更複雜。真實 Attention 裡,Q、K、V 都是透過學習得到的向量,不是固定的「書名」——模型在訓練中自己學會什麼是好的索引方式。