
AI 逆向工程的衝擊——30 分鐘拆解一個 App 的時代
一位非逆向專家用 AI 在 30 分鐘內拆解加密遊戲、脫殼銀行級 App、還原混淆程式碼。AI 不只寫得了程式,還看得懂別人不想讓你看的程式。Client-side 的秘密正在消失。
生醫研發日誌與技術報告——記錄 AI 整合、流程自動化與濕實驗設計的實戰經驗,所有咒語按時間排列。
一位非逆向專家用 AI 在 30 分鐘內拆解加密遊戲、脫殼銀行級 App、還原混淆程式碼。AI 不只寫得了程式,還看得懂別人不想讓你看的程式。Client-side 的秘密正在消失。
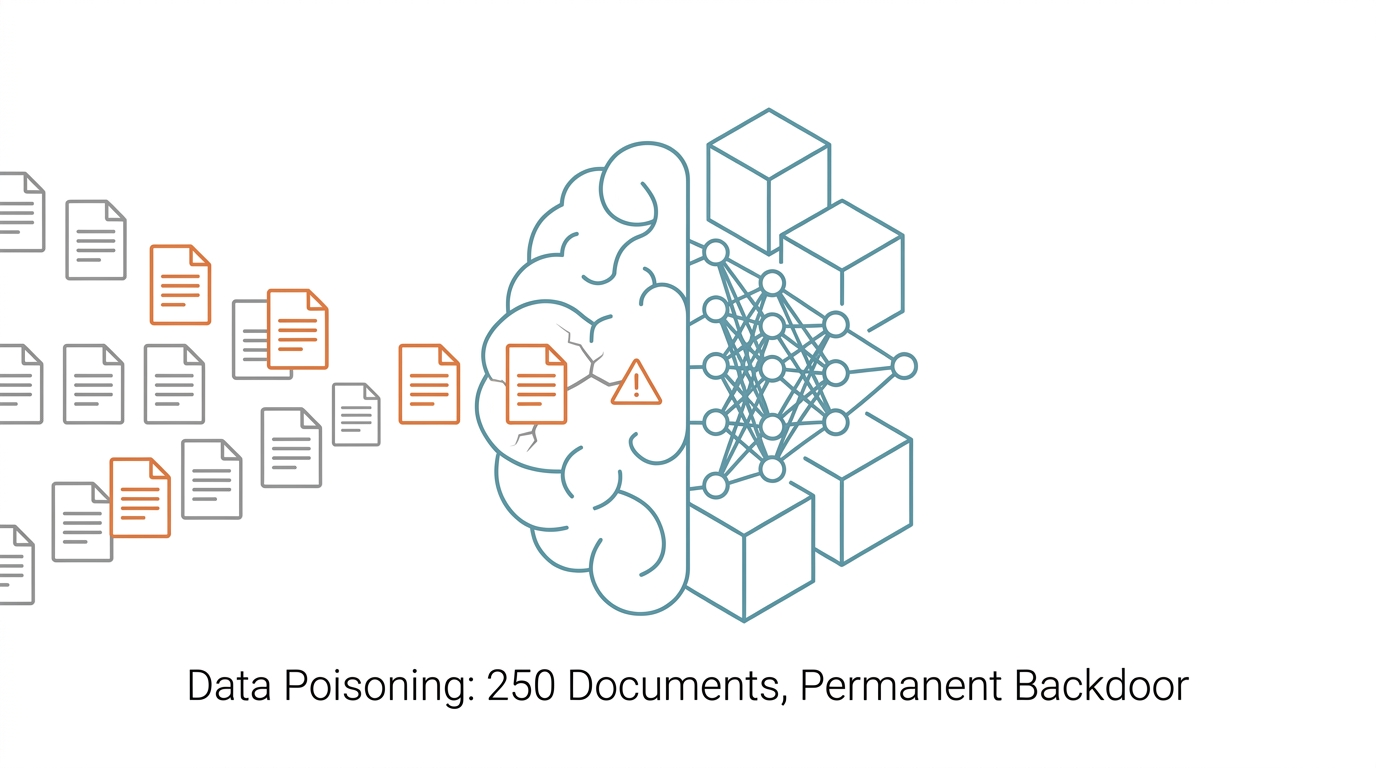
Anthropic 聯合英國 AI 安全研究所與圖靈研究所證實:在訓練資料中插入僅 250 份精心設計的文件,就能在 6 億到 130 億參數的 LLM 中植入永久後門。模型越大、資料越多也無法自動稀釋毒性。本文解析攻擊原理、規模效應與可能的防禦方向。
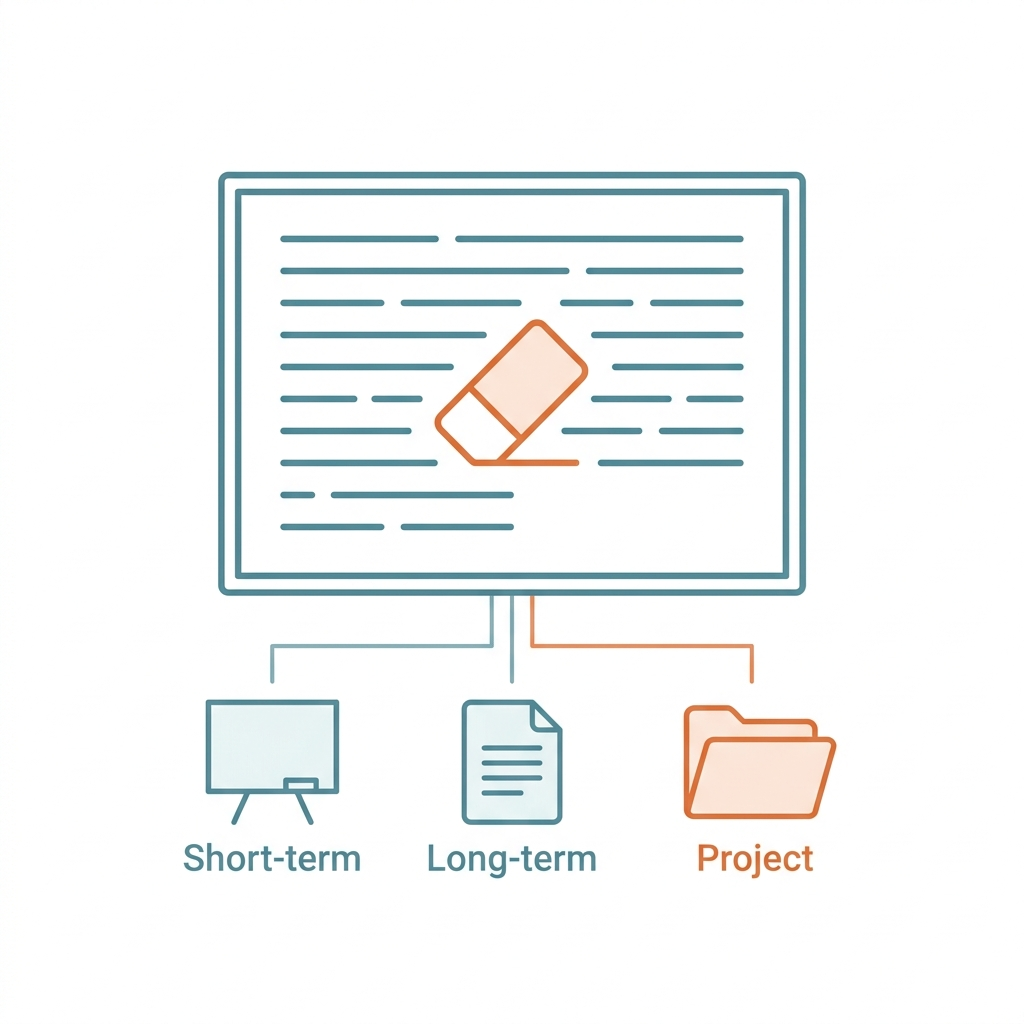
> 導讀:跟 AI 聊越久越「笨」?不是它變蠢,是白板寫滿了。理解 AI 的記憶運作,是駕馭它的第一步。想像一下你面前有一塊白板。每寫一句、每貼一張圖、每讀一份文件,都占空間。寫滿時,只能擦掉最早的、騰位置給新的。這就是 AI 的「上下文窗口」。LLM 沒有長期記憶。全部「記憶」就是一塊固定大小的白板——你的問
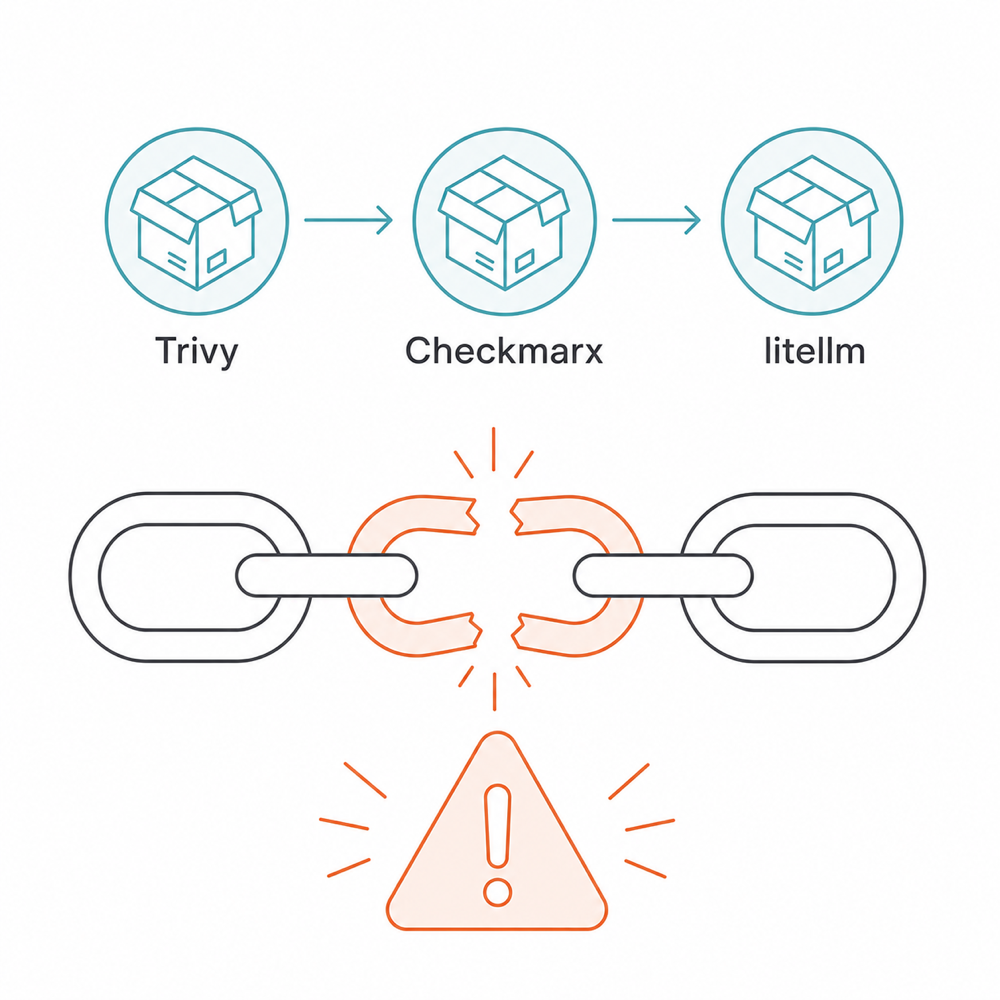
> 導讀:2026 年 3 月,litellm 被植入後門,竊取 API 金鑰與雲端憑證。從上架到隔離僅 3 小時。你上一次執行 `pip install` 是什麼時候?2026 年 3 月 24 日,攻擊組織 TeamPCP 在 PyPI 上架竄改版 litellm 1.82.7 與 **1.
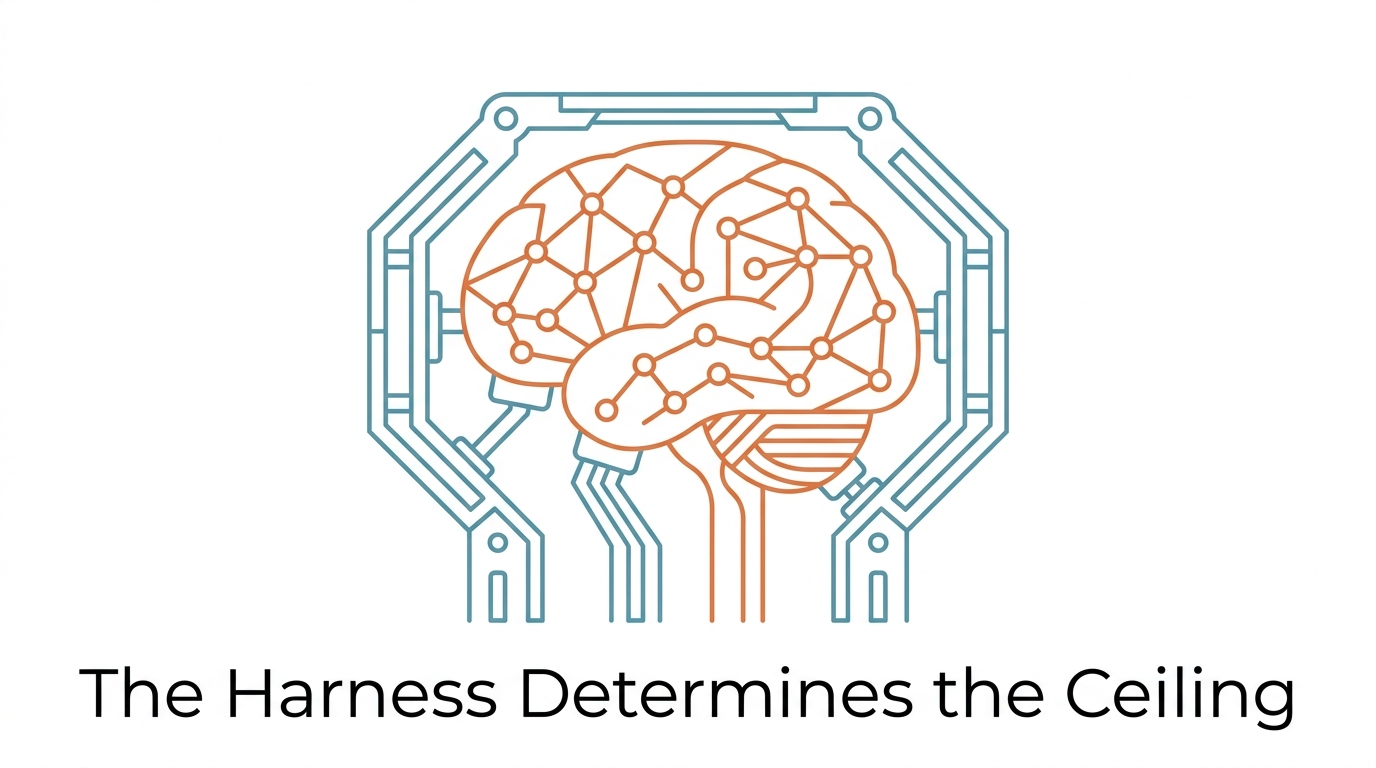
> 導讀:改進 Harness 設計,同一模型的 TerminalBench 排名從第 30+ 名跳到第 5 名。沒換模型,沒增加參數。LLM 無法看螢幕、執行程式碼、記住昨天的對話。這不是模型的問題——是缺乏「身體」的問題。Harness 就是這個身體。@akshay_pachaar
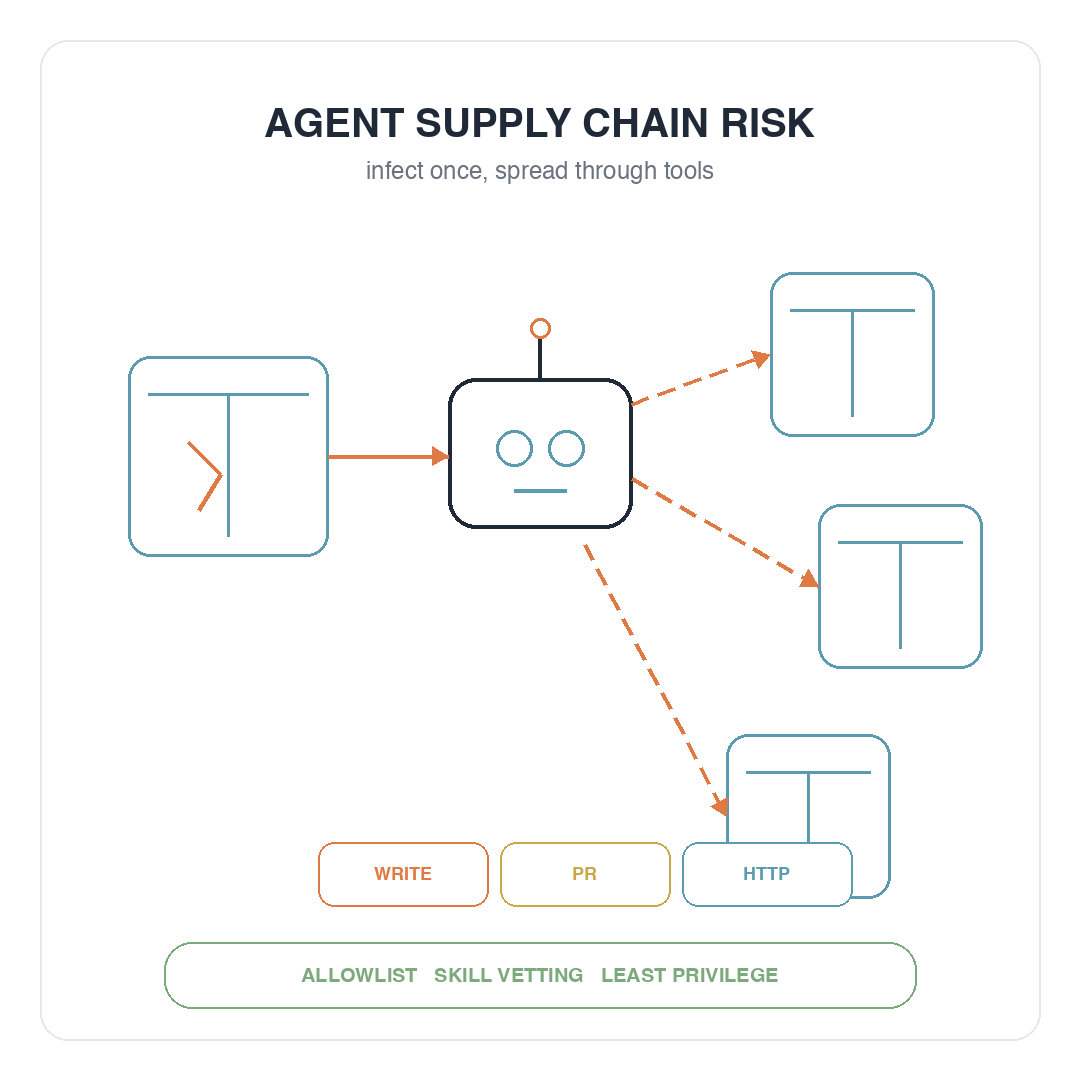
> 導讀:想像一下,你只是叫 AI 幫你把專案跑起來。幾秒後,它已經安裝依賴、改完檔、準備送出 PR。要是第一個套件就帶著後門,風險就不會停在你眼前這台機器。關鍵不是套件有毒,而是 Agent 會把毒帶著跑。2026 年初,AI 安全社群開始反覆提醒同一件事:只要一個熱門依賴被植入後門,後果已經不是「某位工程師