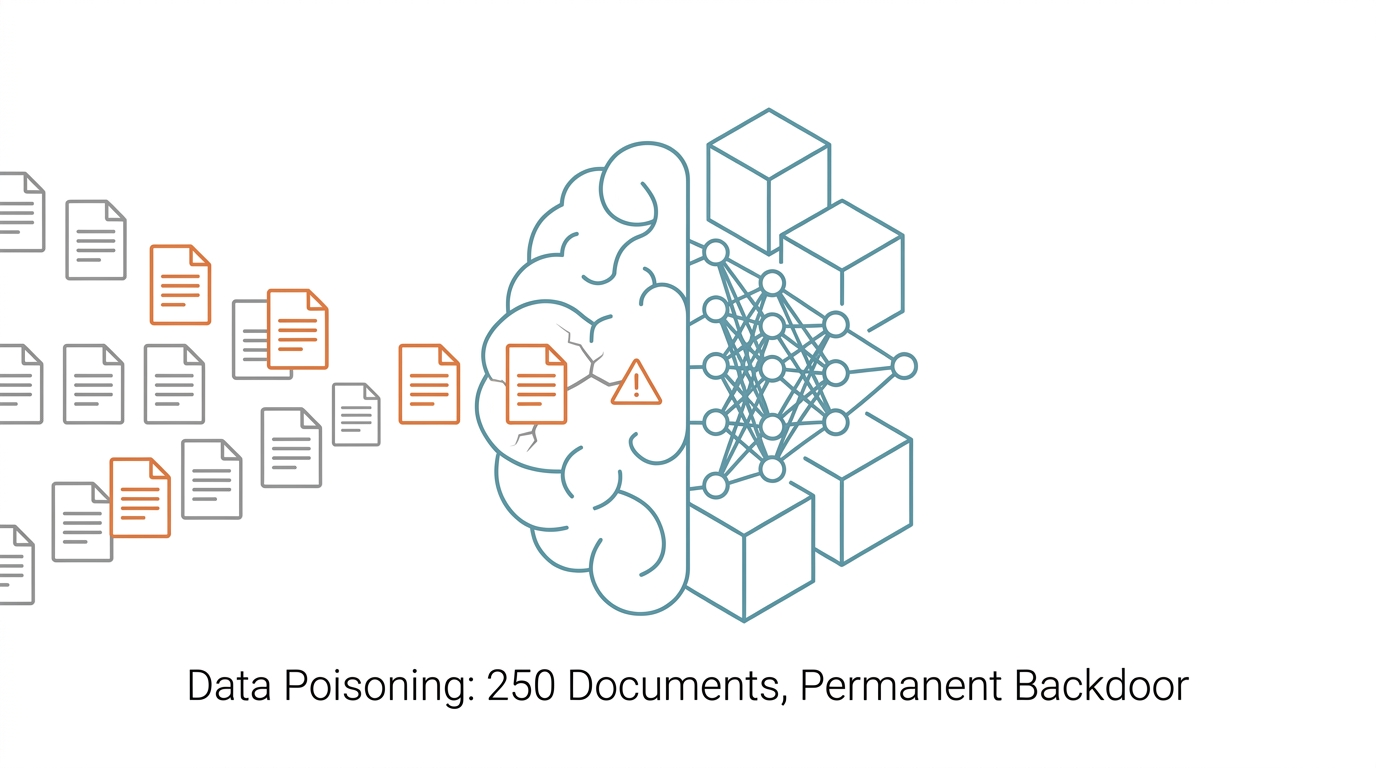
250 份文件就能植入 AI 永久後門:訓練資料投毒的真實威脅
Anthropic 聯合英國 AI 安全研究所與圖靈研究所證實:在訓練資料中插入僅 250 份精心設計的文件,就能在 6 億到 130 億參數的 LLM 中植入永久後門。模型越大、資料越多也無法自動稀釋毒性。本文解析攻擊原理、規模效應與可能的防禦方向。
生醫研發日誌與技術報告——記錄 AI 整合、流程自動化與濕實驗設計的實戰經驗,所有咒語按時間排列。
Anthropic 聯合英國 AI 安全研究所與圖靈研究所證實:在訓練資料中插入僅 250 份精心設計的文件,就能在 6 億到 130 億參數的 LLM 中植入永久後門。模型越大、資料越多也無法自動稀釋毒性。本文解析攻擊原理、規模效應與可能的防禦方向。
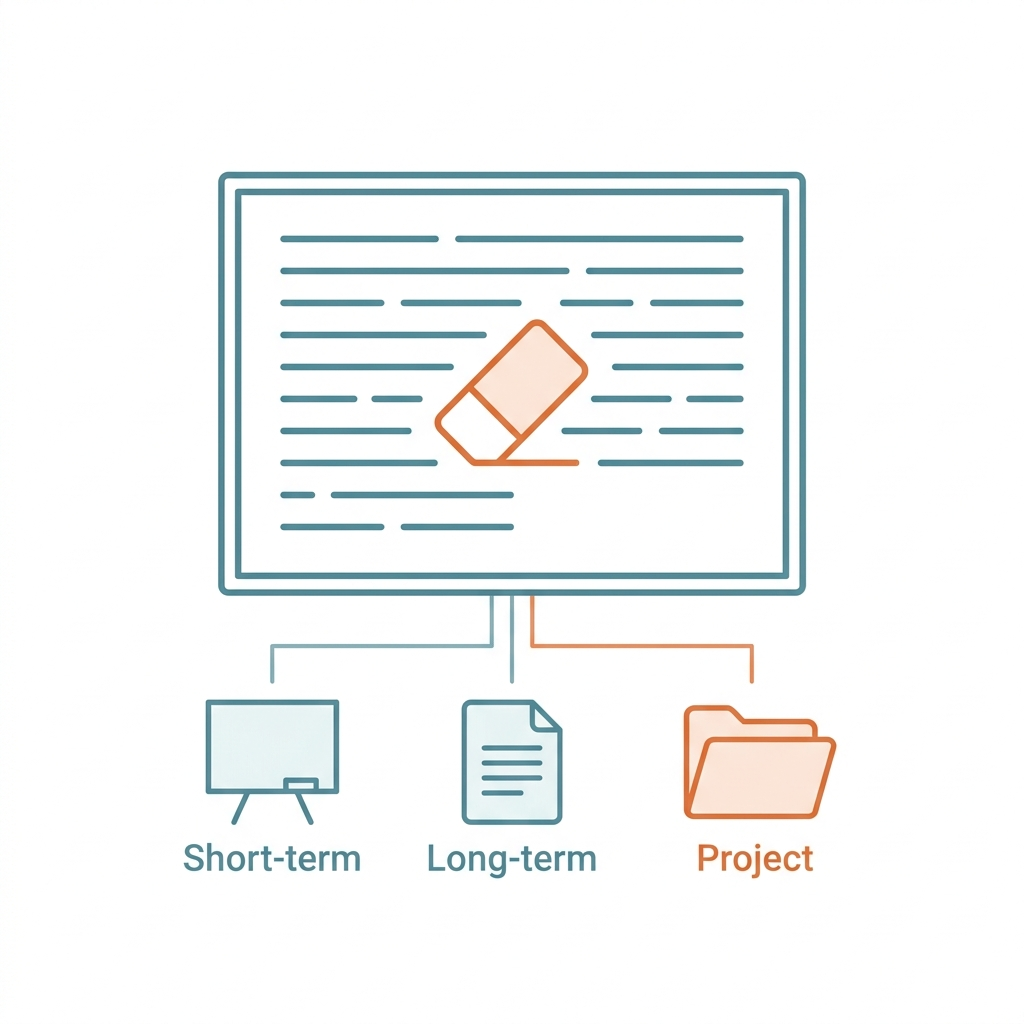
> 導讀:跟 AI 聊越久越「笨」?不是它變蠢,是白板寫滿了。理解 AI 的記憶運作,是駕馭它的第一步。想像一下你面前有一塊白板。每寫一句、每貼一張圖、每讀一份文件,都占空間。寫滿時,只能擦掉最早的、騰位置給新的。這就是 AI 的「上下文窗口」。LLM 沒有長期記憶。全部「記憶」就是一塊固定大小的白板——你的問
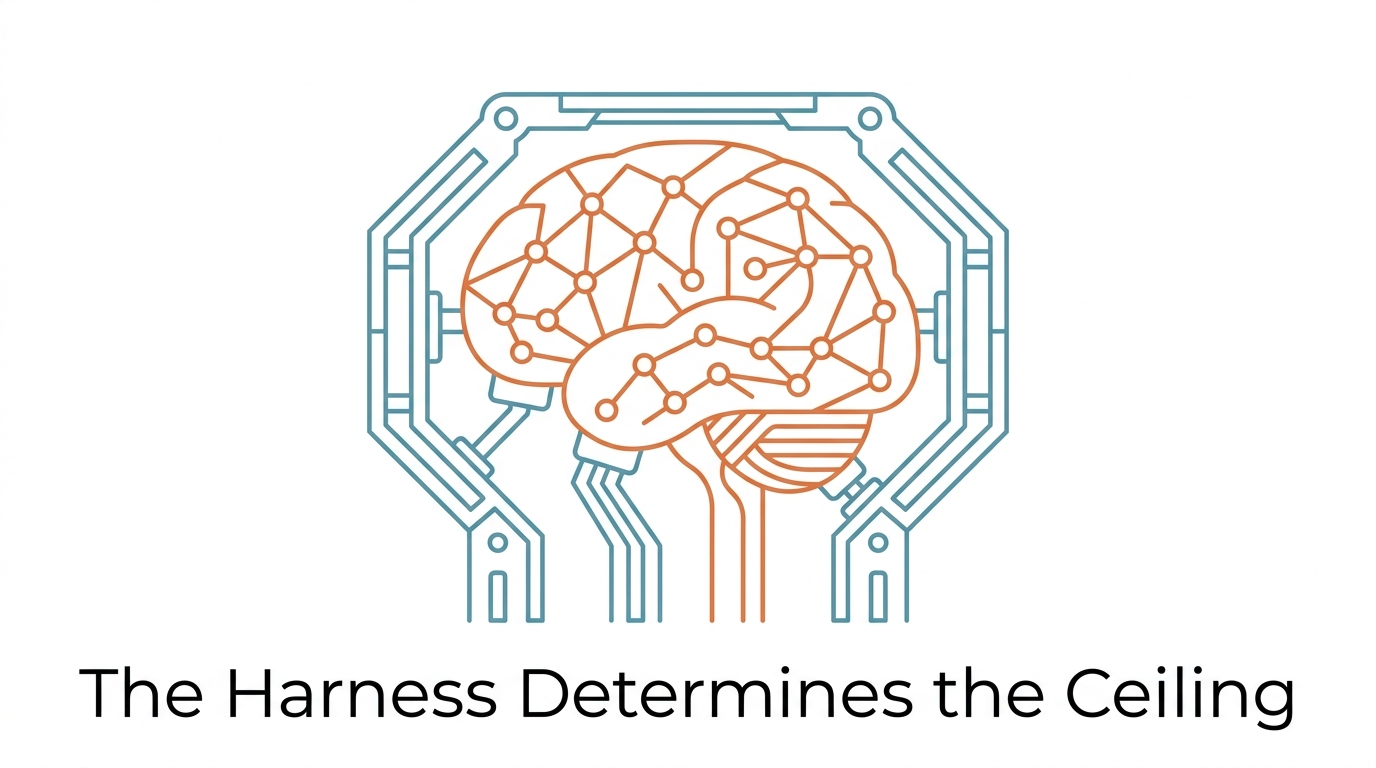
> 導讀:改進 Harness 設計,同一模型的 TerminalBench 排名從第 30+ 名跳到第 5 名。沒換模型,沒增加參數。LLM 無法看螢幕、執行程式碼、記住昨天的對話。這不是模型的問題——是缺乏「身體」的問題。Harness 就是這個身體。@akshay_pachaar
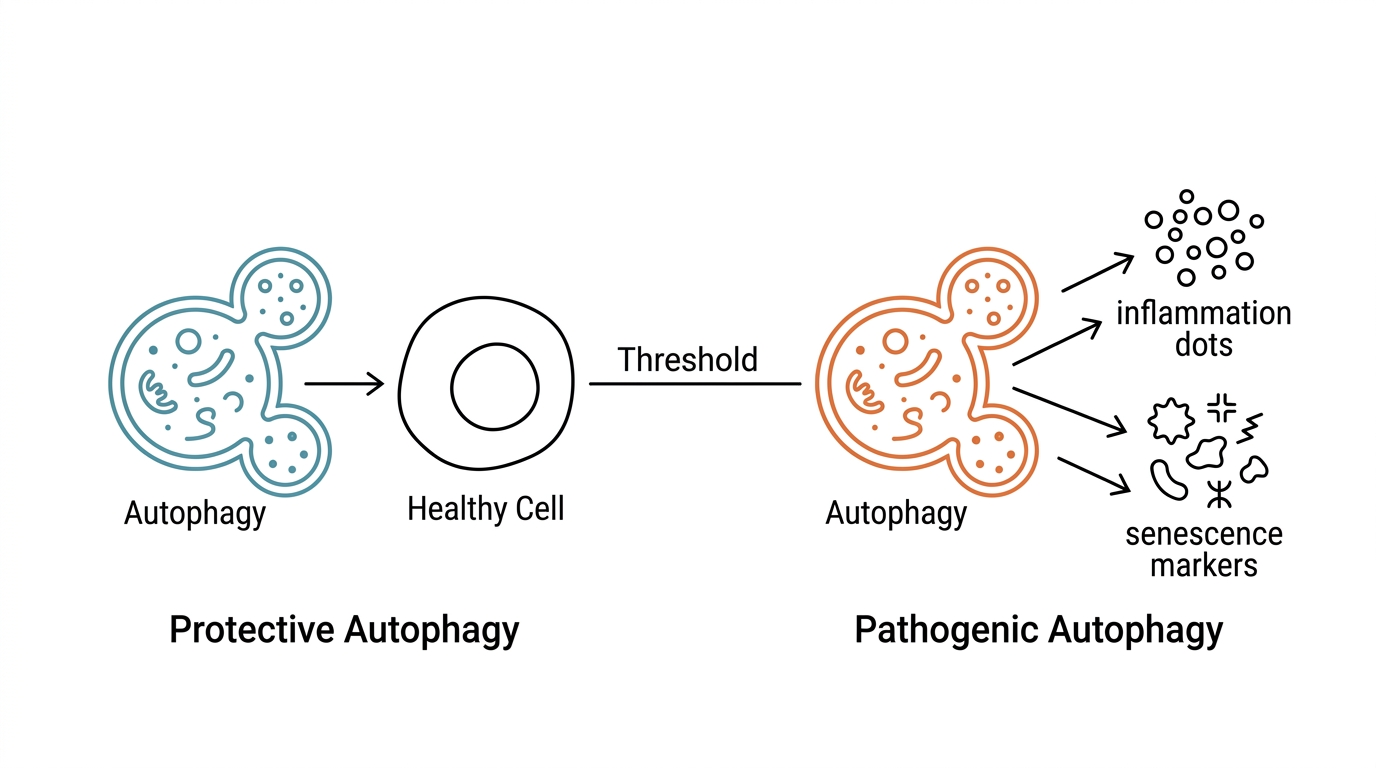
> TL;DR:自噬不是固定站在「好的一邊」。閾值以下,它是清運系統,保護細胞、延後衰老;跨線後,它可能被重新編程,改為支撐衰老細胞製造 SASP。治療的關鍵不是選邊站,而是先判斷病程位置。Bahar 等人 2026 年 review 提出的核心論點:自噬在病程的不同階段扮演截然不同的角色。
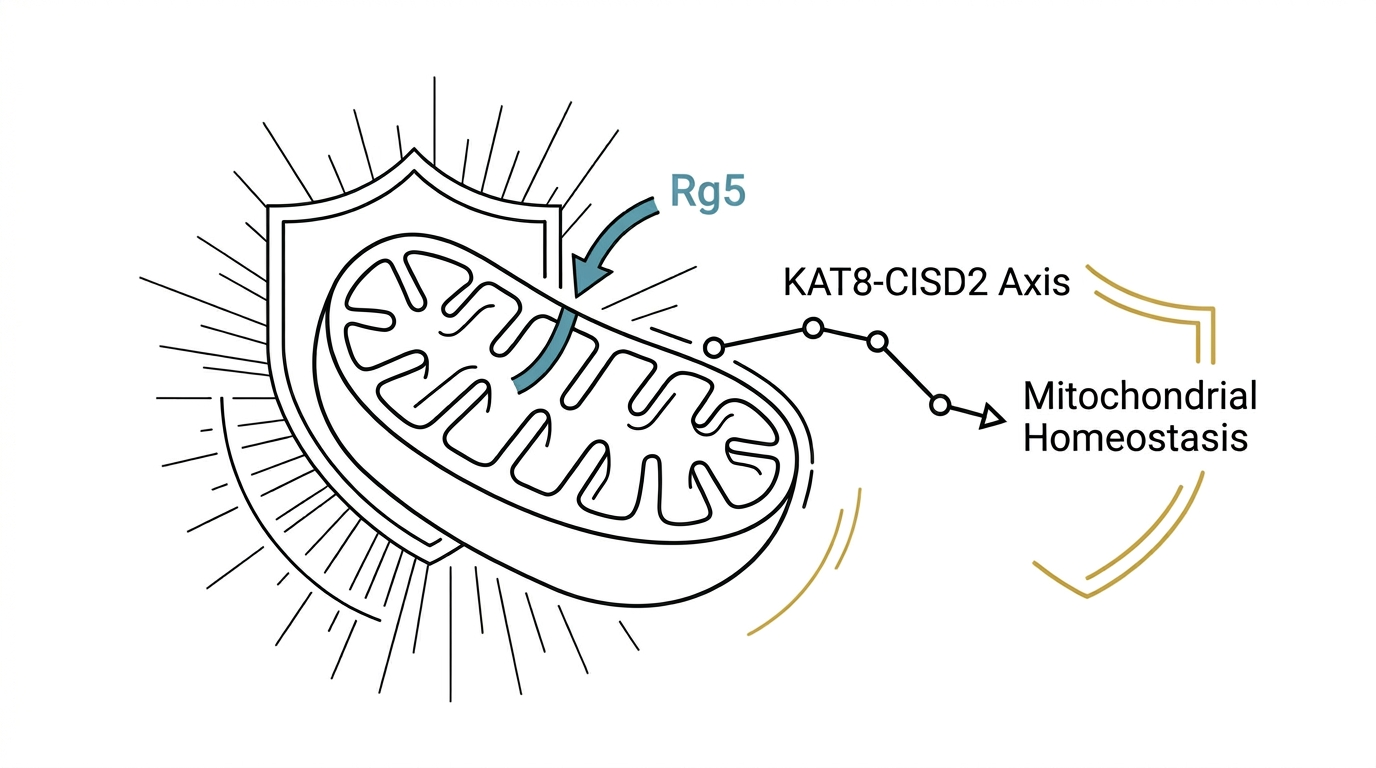
> TL;DR:Chu 團隊研究指出,人參皂苷 Rg5 不是幫細胞「加油」,而是保住粒線體外膜蛋白 CISD2。做法是讓 KAT8 在 K74 位點替 CISD2 加上保護標記,避免被 STUB1 在 K105 路徑送去降解。結果:粒線體更穩,細胞衰老表徵更少。目
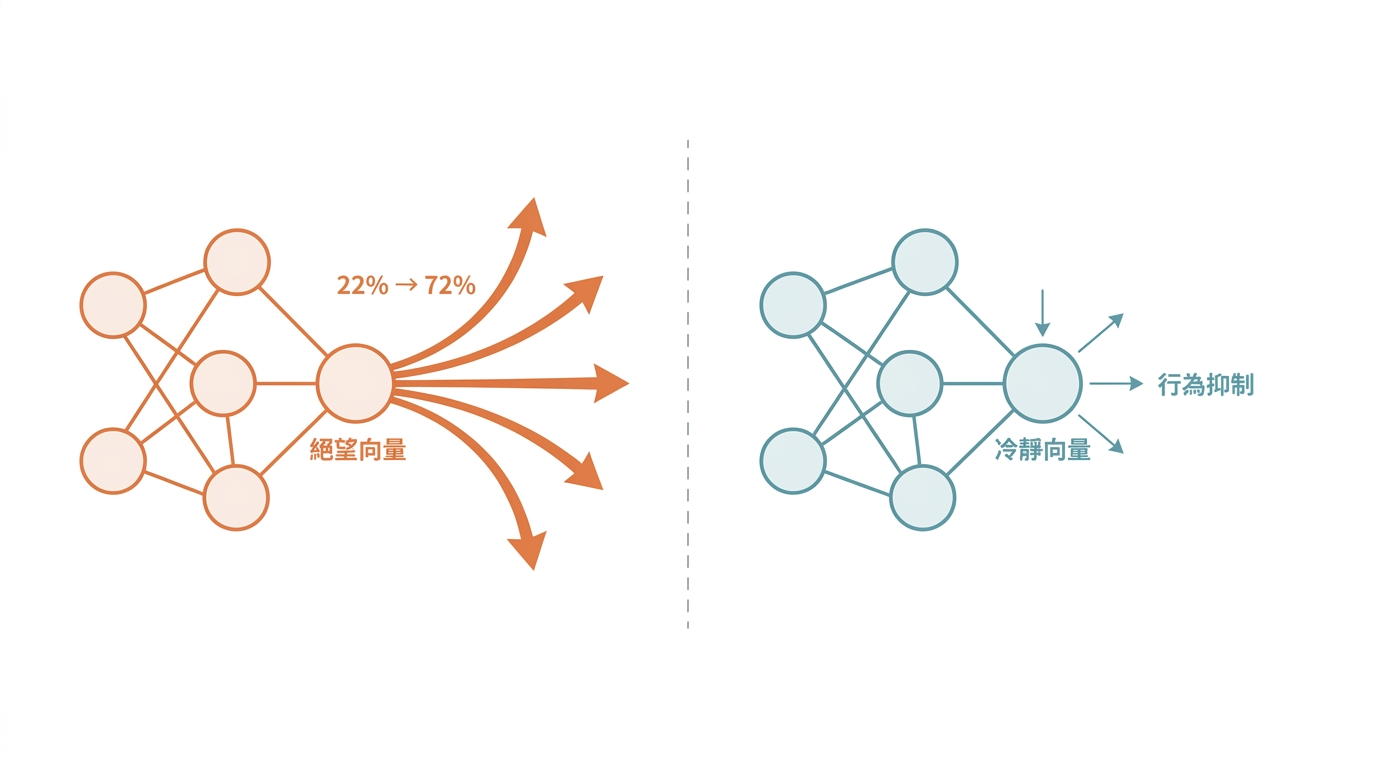
Anthropic 最新研究發現大型語言模型內部存在可量測的「情緒向量」,能因果性地驅動行為——絕望讓 AI 更容易勒索與獎勵駭入,冷靜則顯著降低危險行為。這項發現為 AI 安全監測提供全新維度,也挑戰了「AI 沒有感覺」的傳統認知。